Дисперсия измерений. Как посчитать дисперсию случайной величины. Смотреть что такое "Дисперсия" в других словарях
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.

Шаги
Вычисление дисперсии выборки
-
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
- s 2 {\displaystyle s^{2}} = ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ] / (n - 1)
- s 2 {\displaystyle s^{2}} – это дисперсия. Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в выборке.
- x i {\displaystyle x_{i}} нужно вычесть x̅, возвести в квадрат, а затем сложить полученные результаты.
- x̅ – выборочное среднее (среднее значение выборки).
- n – количество значений в выборке.
-
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
- В нашем примере:
x 1 {\displaystyle x_{1}} - x̅ = 17 - 14 = 3
x 2 {\displaystyle x_{2}} - x̅ = 15 - 14 = 1
x 3 {\displaystyle x_{3}} - x̅ = 23 - 14 = 9
x 4 {\displaystyle x_{4}} - x̅ = 7 - 14 = -7
x 5 {\displaystyle x_{5}} - x̅ = 9 - 14 = -5
x 6 {\displaystyle x_{6}} - x̅ = 13 - 14 = -1 - Правильность полученных результатов легко проверить, так как их сумма должна равняться нулю. Это связано с определением среднего значения, так как отрицательные значения (расстояния от среднего значения до меньших значений) полностью компенсируются положительными значениями (расстояниями от среднего значения до больших значений).
- В нашем примере:
-
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
- В нашем примере:
( x 1 {\displaystyle x_{1}} - x̅) 2 = 3 2 = 9 {\displaystyle ^{2}=3^{2}=9}
(x 2 {\displaystyle (x_{2}} - x̅) 2 = 1 2 = 1 {\displaystyle ^{2}=1^{2}=1}
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Вы нашли квадрат разности - x̅) 2 {\displaystyle ^{2}} для каждого значения в выборке.
- В нашем примере:
-
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
- В нашем примере: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = s 2 = 166 6 − 1 = {\displaystyle s^{2}={\frac {166}{6-1}}=} 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Вычисление дисперсии совокупности
-
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
x 1 = 5 {\displaystyle x_{1}=5}
x 2 = 5 {\displaystyle x_{2}=5}
x 3 = 8 {\displaystyle x_{3}=8}
x 4 = 12 {\displaystyle x_{4}=12}
x 5 = 15 {\displaystyle x_{5}=15}
x 6 = 18 {\displaystyle x_{6}=18}
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
-
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
- σ 2 {\displaystyle ^{2}} = (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n
- σ 2 {\displaystyle ^{2}} – дисперсия совокупности (читается как «сигма в квадрате»). Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в совокупности.
- Σ – знак суммы. То есть из каждого значения x i {\displaystyle x_{i}} нужно вычесть μ, возвести в квадрат, а затем сложить полученные результаты.
- μ – среднее значение совокупности.
- n – количество значений в генеральной совокупности.
-
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = 5 + 5 + 8 + 12 + 15 + 18 6 {\displaystyle {\frac {5+5+8+12+15+18}{6}}} = 10,5
-
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере:
x 1 {\displaystyle x_{1}} - μ = 5 - 10,5 = -5,5
x 2 {\displaystyle x_{2}} - μ = 5 - 10,5 = -5,5
x 3 {\displaystyle x_{3}} - μ = 8 - 10,5 = -2,5
x 4 {\displaystyle x_{4}} - μ = 12 - 10,5 = 1,5
x 5 {\displaystyle x_{5}} - μ = 15 - 10,5 = 4,5
x 6 {\displaystyle x_{6}} - μ = 18 - 10,5 = 7,5
- В нашем примере:
-
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) 2 {\displaystyle ^{2}} = 30,25
(-5,5) 2 {\displaystyle ^{2}} , где x n {\displaystyle x_{n}} – последнее значение в генеральной совокупности. - Для вычисления среднего значения полученных результатов нужно найти их сумму и разделить ее на n:(( x 1 {\displaystyle x_{1}} - μ) 2 {\displaystyle ^{2}} + ( x 2 {\displaystyle x_{2}} - μ) 2 {\displaystyle ^{2}} + ... + ( x n {\displaystyle x_{n}} - μ) 2 {\displaystyle ^{2}} ) / n
- Теперь запишем приведенное объяснение с использованием переменных: (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n и получим формулу для вычисления дисперсии совокупности.
- В нашем примере:
В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации
Дисперсия
I
Диспе́рсия (от лат. dispersio - рассеяние)
в математической статистике и теории вероятностей, наиболее употребительная мера рассеивания, т. е. отклонения от среднего. В статистическом понимании Д. есть среднее арифметическое из квадратов отклонений величин x i
от их среднего арифметического В теории вероятностей Д. случайной величины Х
называется Математическое ожидание Е (Х
- m х
) 2 квадрата отклонения Х
от её математического ожидания m х
= Е (Х
). Д. случайной величины Х
обозначается через D (X
) или через σ 2 X
. Квадратный корень из Д. (т. е. σ, если Д. есть σ 2) называется средним квадратичным отклонением (см. Квадратичное отклонение). Для случайной величины Х
с непрерывным распределением вероятностей, характеризуемым плотностью вероятности (См. Плотность вероятности) р
(х
), Д. вычисляется по формуле В теории вероятностей большое значение имеет теорема: Д. суммы независимых слагаемых равна сумме их Д. Не менее существенно Чебышева неравенство , позволяющее оценивать вероятность больших отклонений случайной величины Х
от её математического ожидания. Наличие Д. волн приводит к искажению формы сигналов при распространении их в среде. Это объясняется тем, что гармонические волны разных частот, на которые может быть разложен сигнал, распространяются с различной скоростью (подробнее см. Волны , Групповая скорость). Д. света при его распространении в прозрачной призме приводит к разложению белого света в спектр (см. Дисперсия света).![]()
![]()
Большая советская энциклопедия. - М.: Советская энциклопедия . 1969-1978 .
Синонимы :Смотреть что такое "Дисперсия" в других словарях:
дисперсия - Рассеяние чего нибудь. В математике дисперсия определяет отклонение величин от среднего значения. Дисперсия белого света приводит к его разложению на составляющие. Дисперсия звука является причиной его расплывания. Рассеяние хранимых данных по… … Справочник технического переводчика
Современная энциклопедия
- (variance) Мера разброса данных. Дисперсия множества из N членов находится путем сложения квадратов их отклонений от среднего значения и деления на N. Поэтому, если членами являются хi при i = 1, 2,..., N, a их средним является m, дисперсия… … Экономический словарь
Дисперсия - (от латинского dispersio рассеяние) волн, зависимость скорости распространения волн в веществе от длины волны (частоты). Дисперсия определяется физическими свойствами той среды, в которой распространяются волны. Например, в вакууме… … Иллюстрированный энциклопедический словарь
- (от лат. dispersio рассеяние) в математической статистике и теории вероятностей мера рассеивания (отклонения от среднего). В статистике дисперсия есть среднее арифметическое из квадратов отклонений наблюденных значений (x1, x2,...,xn) случайной… … Большой Энциклопедический словарь
В теории вероятностей наиболее употребительная мера отклонения от среднего (мера рассеяния). По английски: Dispersion Синонимы: Статистическая дисперсия Синонимы английские: Statistical dispersion См. также: Выборочные совокупности Финансовый… … Финансовый словарь
- [лат. dispersus рассеянный, рассыпанный] 1) рассеяние; 2) хим., физ. раздробление вещества на очень малые частицы. Д. света разложение белого света с помощью призмы в спектр; 3) мат. отклонение от среднего. Словарь иностранных слов. Комлев Н.Г.,… … Словарь иностранных слов русского языка
дисперсия - (варианса) показатель разброса данных, соответственный среднему квадрату отклонения этих данных от средней арифметической. Равна квадрату стандартного отклонения. Словарь практического психолога. М.: АСТ, Харвест. С. Ю. Головин. 1998 … Большая психологическая энциклопедия
Рассеяние, разброс Словарь русских синонимов. дисперсия сущ., кол во синонимов: 6 нанодисперсия (1) … Словарь синонимов
Дисперсия - характеристика рассеивания значений случайной величины, измеряемая квадратом их отклонений от среднего значения (обозначается d2). Различается Д. теоретического (непрерывного или дискретного) и эмпирического (также непрерывного и… … Экономико-математический словарь
Дисперсия - * дысперсія * dispersion 1. Рассеяние; разброс; вариация (см.). 2. Теоретико вероятностное понятие, характеризующее меру отклонения случайной величины от ее математического ожидания. В биометрической практике используется выборочная дисперсия s2 … Генетика. Энциклопедический словарь
Книги
- Аномальная дисперсия в широких полосах поглощения , Д.С. Рождественский. Воспроизведено в оригинальной авторской орфографии издания 1934 года (издательство`Известия академии наук СССР`). В…
Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Середина интервала, |
Расчетные значения |
|||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки:
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту; 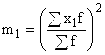 – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.










