Die Methode der kleinsten Quadrate ist in der Gruppe enthalten. Ein Beispiel ist ein System linearer Gleichungen. Beispiele für die Lösung spezifischer Probleme
Methode der kleinsten Quadrate Wird zur Schätzung der Parameter der Regressionsgleichung verwendet.Eine der Methoden zur Untersuchung stochastischer Beziehungen zwischen Merkmalen ist die Regressionsanalyse.
Unter Regressionsanalyse versteht man die Ableitung einer Regressionsgleichung, mit deren Hilfe der Durchschnittswert einer Zufallsvariablen (Ergebnisattribut) ermittelt wird, wenn der Wert einer anderen (oder anderer) Variablen (Faktorattribute) bekannt ist. Es umfasst die folgenden Schritte:
- Auswahl der Verbindungsform (Art der analytischen Regressionsgleichung);
- Schätzung von Gleichungsparametern;
- Beurteilung der Qualität der analytischen Regressionsgleichung.
Im Fall einer linearen paarweisen Beziehung nimmt die Regressionsgleichung die Form an: y i =a+b·x i +u i . Die Parameter a und b dieser Gleichung werden aus statistischen Beobachtungsdaten x und y geschätzt. Das Ergebnis einer solchen Bewertung ist die Gleichung: , wobei , Schätzungen der Parameter a und b sind, der Wert des resultierenden Attributs (der Variablen) ist, das aus der Regressionsgleichung erhalten wird (berechneter Wert).
Wird am häufigsten zum Schätzen von Parametern verwendet Methode der kleinsten Quadrate (LSM).
Die Methode der kleinsten Quadrate liefert die besten (konsistenten, effizienten und unvoreingenommenen) Schätzungen der Parameter der Regressionsgleichung. Allerdings nur, wenn bestimmte Annahmen bezüglich des Zufallsterms (u) und der unabhängigen Variablen (x) erfüllt sind (siehe OLS-Annahmen).
Das Problem der Schätzung der Parameter einer linearen Paargleichung mithilfe der Methode der kleinsten Quadrate ist wie folgt: um solche Schätzungen von Parametern zu erhalten , , bei denen die Summe der quadratischen Abweichungen der tatsächlichen Werte des resultierenden Merkmals – y i von den berechneten Werten – minimal ist.
Formal OLS-Test kann so geschrieben werden:  .
.
Klassifizierung der Methode der kleinsten Quadrate
- Methode der kleinsten Quadrate.
- Maximum-Likelihood-Methode (für ein normales klassisches lineares Regressionsmodell wird Normalität der Regressionsresiduen postuliert).
- Bei der Autokorrelation von Fehlern und bei Heteroskedastizität wird die verallgemeinerte Methode der kleinsten Quadrate OLS verwendet.
- Gewichtete Methode der kleinsten Quadrate (ein Sonderfall von OLS mit heteroskedastischen Residuen).
Lassen Sie uns den Punkt veranschaulichen klassische Methode der kleinsten Quadrate grafisch. Dazu erstellen wir ein Streudiagramm basierend auf Beobachtungsdaten (x i, y i, i=1;n) in einem rechteckigen Koordinatensystem (ein solches Streudiagramm wird als Korrelationsfeld bezeichnet). Versuchen wir, eine Gerade auszuwählen, die den Punkten des Korrelationsfelds am nächsten liegt. Nach der Methode der kleinsten Quadrate wird die Gerade so gewählt, dass die Summe der Quadrate der vertikalen Abstände zwischen den Punkten des Korrelationsfeldes und dieser Geraden minimal ist. 
Mathematische Notation für dieses Problem:  .
.
Die Werte von y i und x i =1...n sind uns bekannt, es handelt sich um Beobachtungsdaten. In der S-Funktion stellen sie Konstanten dar. Die Variablen in dieser Funktion sind die erforderlichen Schätzungen der Parameter - , . Um das Minimum einer Funktion zweier Variablen zu finden, ist es notwendig, die partiellen Ableitungen dieser Funktion für jeden der Parameter zu berechnen und sie mit Null gleichzusetzen, d.h. 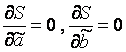 .
.
Als Ergebnis erhalten wir ein System aus 2 normalen linearen Gleichungen: 
Wenn wir dieses System lösen, finden wir die erforderlichen Parameterschätzungen: 
Die Richtigkeit der Berechnung der Parameter der Regressionsgleichung kann durch Vergleich der Beträge überprüft werden (durch Rundung der Berechnungen kann es zu Abweichungen kommen).
Um Parameterschätzungen zu berechnen, können Sie Tabelle 1 erstellen.
Das Vorzeichen des Regressionskoeffizienten b gibt die Richtung der Beziehung an (wenn b > 0, ist die Beziehung direkt, wenn b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formal ist der Wert des Parameters a der Durchschnittswert von y, wobei x gleich Null ist. Wenn der Attributfaktor keinen Nullwert hat und haben kann, dann ist die obige Interpretation des Parameters a nicht sinnvoll.
Beurteilung der Nähe der Beziehung zwischen Merkmalen
durchgeführt unter Verwendung des linearen Paarkorrelationskoeffizienten - r x,y. Es kann mit der Formel berechnet werden:  . Darüber hinaus kann der lineare Paarkorrelationskoeffizient durch den Regressionskoeffizienten b bestimmt werden:
. Darüber hinaus kann der lineare Paarkorrelationskoeffizient durch den Regressionskoeffizienten b bestimmt werden:  .
.
Der Bereich akzeptabler Werte des linearen Paarkorrelationskoeffizienten liegt zwischen –1 und +1. Das Vorzeichen des Korrelationskoeffizienten gibt die Richtung der Beziehung an. Wenn r x, y >0, dann ist die Verbindung direkt; wenn r x, y<0, то связь обратная.
Liegt dieser Koeffizient betragsmäßig nahe bei eins, kann die Beziehung zwischen den Merkmalen als ziemlich eng linear interpretiert werden. Wenn sein Modul gleich eins ê r x , y ê =1 ist, dann ist die Beziehung zwischen den Merkmalen funktional linear. Wenn die Merkmale x und y linear unabhängig sind, liegt r x,y nahe bei 0.
Zur Berechnung von r x,y können Sie auch Tabelle 1 verwenden.
Tabelle 1
| N Beobachtungen | x i | y i | x i ∙y i | ||
| 1 | x 1 | Jahr 1 | x 1 y 1 | ||
| 2 | x 2 | Jahr 2 | x 2 y 2 | ||
| ... | |||||
| N | x n | y n | x n y n | ||
| Spaltensumme | ∑x | ∑y | ∑xy | ||
| Mittlere Bedeutung |
|
|
 ,
,
wobei d 2 die Varianz von y ist, die durch die Regressionsgleichung erklärt wird;
e 2 – Restvarianz (nicht durch die Regressionsgleichung erklärt) von y;
s 2 y - Gesamtvarianz von y.
Das Bestimmtheitsmaß charakterisiert den Anteil der durch Regression erklärten Variation (Streuung) des resultierenden Attributs y (und damit des Faktors x) an der Gesamtvariation (Streuung) y. Das Bestimmtheitsmaß R 2 yx nimmt Werte von 0 bis 1 an. Dementsprechend charakterisiert der Wert 1-R 2 yx den Anteil der Varianz y, der durch den Einfluss anderer im Modell nicht berücksichtigter Faktoren und Spezifikationsfehler verursacht wird.
Bei gepaarter linearer Regression ist R 2 yx =r 2 yx.
Es hat viele Anwendungsmöglichkeiten, da es eine näherungsweise Darstellung einer gegebenen Funktion durch andere, einfachere Funktionen ermöglicht. LSM kann bei der Verarbeitung von Beobachtungen äußerst nützlich sein und wird aktiv verwendet, um einige Größen auf der Grundlage der Messergebnisse anderer zu schätzen, die zufällige Fehler enthalten. In diesem Artikel erfahren Sie, wie Sie Berechnungen der kleinsten Quadrate in Excel implementieren.
Darstellung des Problems anhand eines konkreten Beispiels
Angenommen, es gibt zwei Indikatoren X und Y. Darüber hinaus hängt Y von X ab. Da OLS uns aus Sicht der Regressionsanalyse interessiert (in Excel werden seine Methoden mithilfe integrierter Funktionen implementiert), sollten wir sofort mit der Betrachtung von a fortfahren spezifisches Problem.
Sei also X die Verkaufsfläche eines Lebensmittelgeschäfts, gemessen in Quadratmetern, und Y der Jahresumsatz, gemessen in Millionen Rubel.
Es ist erforderlich, eine Prognose darüber zu erstellen, welchen Umsatz (Y) das Geschäft erzielen wird, wenn es über diese oder jene Verkaufsfläche verfügt. Offensichtlich nimmt die Funktion Y = f (X) zu, da der Hypermarkt mehr Waren verkauft als der Stand.
Ein paar Worte zur Richtigkeit der für die Vorhersage verwendeten Ausgangsdaten
Nehmen wir an, wir haben eine Tabelle, die mit Daten für n Filialen erstellt wurde.
Laut mathematischer Statistik sind die Ergebnisse mehr oder weniger korrekt, wenn Daten zu mindestens 5-6 Objekten untersucht werden. Darüber hinaus können „anomale“ Ergebnisse nicht verwendet werden. Insbesondere eine kleine Elite-Boutique kann einen Umsatz erzielen, der um ein Vielfaches höher ist als der Umsatz großer Einzelhandelsgeschäfte der „Masmarket“-Klasse.
Die Essenz der Methode
Die Tabellendaten können auf einer kartesischen Ebene in Form von Punkten M 1 (x 1, y 1), ... M n (x n, y n) dargestellt werden. Nun reduziert sich die Lösung des Problems auf die Auswahl einer Näherungsfunktion y = f (x), die einen Graphen aufweist, der möglichst nahe an den Punkten M 1, M 2, .. M n verläuft.
Natürlich können Sie ein Polynom höheren Grades verwenden, aber diese Option ist nicht nur schwierig zu implementieren, sondern auch einfach falsch, da sie nicht den Haupttrend widerspiegelt, der erkannt werden muss. Die sinnvollste Lösung besteht darin, nach der Geraden y = ax + b zu suchen, die den experimentellen Daten, genauer gesagt den Koeffizienten a und b, am besten entspricht.
Genauigkeitsbewertung
Bei jeder Näherung ist die Beurteilung ihrer Genauigkeit von besonderer Bedeutung. Bezeichnen wir mit e i die Differenz (Abweichung) zwischen den funktionalen und experimentellen Werten für den Punkt x i, d.h. e i = y i - f (x i).
Um die Genauigkeit der Näherung zu beurteilen, können Sie natürlich die Summe der Abweichungen verwenden, d. h. wenn Sie eine Gerade für eine ungefähre Darstellung der Abhängigkeit von X von Y wählen, sollten Sie der Linie mit dem kleinsten Wert den Vorzug geben Summe e i an allen betrachteten Punkten. Allerdings ist nicht alles so einfach, denn neben positiven Abweichungen gibt es auch negative.
Das Problem kann mithilfe von Abweichungsmodulen oder deren Quadraten gelöst werden. Die letzte Methode ist die am weitesten verbreitete. Es wird in vielen Bereichen eingesetzt, einschließlich der Regressionsanalyse (implementiert in Excel mithilfe zweier integrierter Funktionen), und hat seine Wirksamkeit seit langem bewiesen.
Methode der kleinsten Quadrate
Wie Sie wissen, verfügt Excel über eine integrierte AutoSumme-Funktion, mit der Sie die Werte aller Werte berechnen können, die sich im ausgewählten Bereich befinden. Somit hindert uns nichts daran, den Wert des Ausdrucks (e 1 2 + e 2 2 + e 3 2 + ... e n 2) zu berechnen.
In mathematischer Notation sieht das so aus:

Da ursprünglich die Entscheidung getroffen wurde, mit einer geraden Linie zu approximieren, gilt:

Die Aufgabe, die Gerade zu finden, die die spezifische Abhängigkeit der Größen X und Y am besten beschreibt, besteht also darin, das Minimum einer Funktion zweier Variablen zu berechnen:

Dazu müssen Sie die partiellen Ableitungen nach den neuen Variablen a und b mit Null gleichsetzen und ein primitives System lösen, das aus zwei Gleichungen mit zwei Unbekannten der Form besteht:

Nach einigen einfachen Transformationen, einschließlich Division durch 2 und Manipulation von Summen, erhalten wir:

Wenn wir es beispielsweise mit der Cramer-Methode lösen, erhalten wir einen stationären Punkt mit bestimmten Koeffizienten a * und b *. Dies ist das Minimum, d.h. um vorherzusagen, welchen Umsatz ein Geschäft für eine bestimmte Fläche haben wird, eignet sich die Gerade y = a * x + b*, die für das jeweilige Beispiel ein Regressionsmodell darstellt. Natürlich können Sie damit nicht das genaue Ergebnis finden, aber es hilft Ihnen, sich ein Bild davon zu machen, ob sich der Kauf einer bestimmten Fläche auf Guthaben auszahlt.
So implementieren Sie die Methode der kleinsten Quadrate in Excel
Excel verfügt über eine Funktion zur Berechnung von Werten mithilfe der Methode der kleinsten Quadrate. Es hat die folgende Form: „TREND“ (bekannte Y-Werte; bekannte X-Werte; neue X-Werte; Konstante). Wenden wir die Formel zur Berechnung von OLS in Excel auf unsere Tabelle an.
Geben Sie dazu das „=“-Zeichen in die Zelle ein, in der das Ergebnis der Berechnung nach der Methode der kleinsten Quadrate in Excel angezeigt werden soll, und wählen Sie die Funktion „TREND“. Füllen Sie im sich öffnenden Fenster die entsprechenden Felder aus und markieren Sie Folgendes:
- Bereich bekannter Werte für Y (in diesem Fall Daten für den Handelsumsatz);
- Bereich x 1 , …x n , d. h. die Größe der Verkaufsfläche;
- sowohl bekannte als auch unbekannte Werte von x, für die Sie die Größe des Umsatzes ermitteln müssen (Informationen zu ihrer Position auf dem Arbeitsblatt finden Sie unten).
Darüber hinaus enthält die Formel die logische Variable „Const“. Wenn Sie in das entsprechende Feld eine 1 eingeben, bedeutet dies, dass Sie die Berechnungen unter der Annahme durchführen sollten, dass b = 0.
Wenn Sie die Prognose für mehr als einen x-Wert ermitteln müssen, sollten Sie nach Eingabe der Formel nicht die Eingabetaste drücken, sondern die Kombination „Umschalttaste“ + „Strg“ + „Eingabetaste“ auf der Tastatur eingeben.
Einige Eigenschaften
Die Regressionsanalyse kann auch für Dummköpfe zugänglich sein. Die Excel-Formel zur Vorhersage des Werts einer Reihe unbekannter Variablen – TREND – kann sogar von denjenigen verwendet werden, die noch nie von der Methode der kleinsten Quadrate gehört haben. Es reicht aus, nur einige Merkmale seiner Arbeit zu kennen. Insbesondere:
- Wenn Sie den Bereich bekannter Werte der Variablen y in einer Zeile oder Spalte anordnen, wird jede Zeile (Spalte) mit bekannten Werten von x vom Programm als separate Variable wahrgenommen.
- Wenn im TREND-Fenster kein Bereich mit bekanntem x angegeben ist, behandelt das Programm ihn bei Verwendung der Funktion in Excel als Array bestehend aus ganzen Zahlen, deren Anzahl dem Bereich mit den angegebenen Werten des entspricht Variable y.
- Um ein Array von „vorhergesagten“ Werten auszugeben, muss der Ausdruck zur Berechnung des Trends als Array-Formel eingegeben werden.
- Wenn keine neuen Werte von x angegeben werden, betrachtet die TREND-Funktion sie als gleich den bekannten. Wenn sie nicht angegeben sind, wird Array 1 als Argument verwendet; 2; 3; 4;…, was dem Bereich mit bereits angegebenen Parametern entspricht y.
- Der Bereich, der die neuen x-Werte enthält, muss die gleichen oder mehr Zeilen oder Spalten haben wie der Bereich, der die angegebenen y-Werte enthält. Mit anderen Worten, es muss proportional zu den unabhängigen Variablen sein.
- Ein Array mit bekannten x-Werten kann mehrere Variablen enthalten. Wenn wir jedoch nur von einem sprechen, ist es erforderlich, dass die Bereiche mit den angegebenen Werten von x und y proportional sind. Bei mehreren Variablen ist es erforderlich, dass der Bereich mit den angegebenen y-Werten in eine Spalte oder eine Zeile passt.

PREDICTION-Funktion
Mit mehreren Funktionen umgesetzt. Eine davon heißt „PREDICTION“. Es ähnelt „TREND“, d. h. es gibt das Ergebnis von Berechnungen nach der Methode der kleinsten Quadrate an. Allerdings nur für ein X, für das der Wert von Y unbekannt ist.
Jetzt kennen Sie Excel-Formeln für Dummies, mit denen Sie den zukünftigen Wert eines bestimmten Indikators anhand eines linearen Trends vorhersagen können.
Approximieren wir die Funktion durch ein Polynom vom Grad 2. Dazu berechnen wir die Koeffizienten des Normalgleichungssystems:
,  ,
, 
Lassen Sie uns ein normales System der kleinsten Quadrate erstellen, das die Form hat:

Die Lösung des Systems ist leicht zu finden: , , .
Somit wird ein Polynom 2. Grades gefunden: .
Theoretische Informationen
Zurück zur Seite<Введение в вычислительную математику. Примеры>
Beispiel 2. Den optimalen Grad eines Polynoms finden.
Zurück zur Seite<Введение в вычислительную математику. Примеры>
Beispiel 3. Herleitung eines normalen Gleichungssystems zur Ermittlung der Parameter der empirischen Abhängigkeit.
Lassen Sie uns ein Gleichungssystem ableiten, um die Koeffizienten und Funktionen zu bestimmen ![]() , das die quadratische Mittelwertnäherung einer gegebenen Funktion durch Punkte durchführt. Lassen Sie uns eine Funktion erstellen
, das die quadratische Mittelwertnäherung einer gegebenen Funktion durch Punkte durchführt. Lassen Sie uns eine Funktion erstellen ![]() und notieren Sie die dafür notwendige Extremumbedingung:
und notieren Sie die dafür notwendige Extremumbedingung:

Dann nimmt das normale System die Form an:

Wir haben ein lineares Gleichungssystem für unbekannte Parameter erhalten, das leicht zu lösen ist.
Theoretische Informationen
Zurück zur Seite<Введение в вычислительную математику. Примеры>
Beispiel.
Experimentelle Daten zu den Werten von Variablen X Und bei sind in der Tabelle angegeben. 
Durch ihre Ausrichtung ergibt sich die Funktion ![]()
Benutzen Methode der kleinsten Quadrate, approximieren Sie diese Daten durch eine lineare Abhängigkeit y=ax+b(Parameter finden A Und B). Finden Sie heraus, welche der beiden Linien (im Sinne der Methode der kleinsten Quadrate) die experimentellen Daten besser anpasst. Fertige eine Zeichnung an.
Die Essenz der Methode der kleinsten Quadrate (LSM).
Die Aufgabe besteht darin, die linearen Abhängigkeitskoeffizienten zu finden, bei denen die Funktion zweier Variablen vorliegt A Und B![]() nimmt den kleinsten Wert an. Das heißt, gegeben A Und B die Summe der quadratischen Abweichungen der experimentellen Daten von der gefundenen Geraden wird am kleinsten sein. Das ist der Sinn der Methode der kleinsten Quadrate.
nimmt den kleinsten Wert an. Das heißt, gegeben A Und B die Summe der quadratischen Abweichungen der experimentellen Daten von der gefundenen Geraden wird am kleinsten sein. Das ist der Sinn der Methode der kleinsten Quadrate.
Bei der Lösung des Beispiels geht es also darum, das Extremum einer Funktion zweier Variablen zu finden.
Ableitung von Formeln zum Finden von Koeffizienten.
Ein System aus zwei Gleichungen mit zwei Unbekannten wird erstellt und gelöst. Ermitteln der partiellen Ableitungen einer Funktion ![]() nach Variablen A Und B, setzen wir diese Ableitungen mit Null gleich.
nach Variablen A Und B, setzen wir diese Ableitungen mit Null gleich. 
Wir lösen das resultierende Gleichungssystem mit einer beliebigen Methode (z. B durch Substitutionsmethode oder Cramer-Methode) und erhalten Sie Formeln zum Ermitteln von Koeffizienten mithilfe der Methode der kleinsten Quadrate (LSM). 
Gegeben A Und B Funktion ![]() nimmt den kleinsten Wert an. Der Beweis dieser Tatsache wird unten im Text am Ende der Seite gegeben.
nimmt den kleinsten Wert an. Der Beweis dieser Tatsache wird unten im Text am Ende der Seite gegeben.
Das ist die ganze Methode der kleinsten Quadrate. Formel zum Finden des Parameters A enthält die Summen , , und Parameter N— Menge experimenteller Daten. Wir empfehlen, die Werte dieser Beträge separat zu berechnen.
Koeffizient B nach Berechnung gefunden A.
Es ist Zeit, sich an das ursprüngliche Beispiel zu erinnern.
Lösung.
In unserem Beispiel n=5. Wir füllen die Tabelle aus, um die Berechnung der Beträge zu erleichtern, die in den Formeln der erforderlichen Koeffizienten enthalten sind. 
Die Werte in der vierten Zeile der Tabelle werden durch Multiplikation der Werte der 2. Zeile mit den Werten der 3. Zeile für jede Zahl erhalten ich.
Die Werte in der fünften Zeile der Tabelle werden durch Quadrieren der Werte in der 2. Zeile für jede Zahl erhalten ich.
Die Werte in der letzten Spalte der Tabelle sind die Summen der Werte in den Zeilen.
Um die Koeffizienten zu ermitteln, verwenden wir die Formeln der Methode der kleinsten Quadrate A Und B. Wir ersetzen darin die entsprechenden Werte aus der letzten Spalte der Tabelle: 
Somit, y = 0,165x+2,184— die gewünschte annähernde Gerade.
Es bleibt abzuwarten, welche der Zeilen y = 0,165x+2,184 oder ![]() nähert sich den Originaldaten besser an, d. h. es wird eine Schätzung mithilfe der Methode der kleinsten Quadrate vorgenommen.
nähert sich den Originaldaten besser an, d. h. es wird eine Schätzung mithilfe der Methode der kleinsten Quadrate vorgenommen.
Fehlerschätzung der Methode der kleinsten Quadrate.
Dazu müssen Sie die Summe der quadrierten Abweichungen der Originaldaten von diesen Linien berechnen ![]() Und
Und ![]() , ein kleinerer Wert entspricht einer Linie, die den Originaldaten im Sinne der Methode der kleinsten Quadrate besser nahekommt.
, ein kleinerer Wert entspricht einer Linie, die den Originaldaten im Sinne der Methode der kleinsten Quadrate besser nahekommt. 
Seit , dann gerade y = 0,165x+2,184 nähert sich den Originaldaten besser an.
Grafische Darstellung der Methode der kleinsten Quadrate (LS).
In den Grafiken ist alles deutlich sichtbar. Die rote Linie ist die gefundene Gerade y = 0,165x+2,184, die blaue Linie ist ![]() , rosa Punkte sind die Originaldaten.
, rosa Punkte sind die Originaldaten.

Warum ist das nötig, warum all diese Näherungen?
Ich persönlich verwende es, um Probleme der Datenglättung, Interpolation und Extrapolation zu lösen (im ursprünglichen Beispiel könnte es darum gehen, den Wert eines beobachteten Werts zu ermitteln). j bei x=3 oder wann x=6 unter Verwendung der Methode der kleinsten Quadrate). Aber wir werden später in einem anderen Abschnitt der Website mehr darüber sprechen.
Seitenanfang
Nachweisen.
Also das, wenn es gefunden wird A Und B Da die Funktion den kleinsten Wert annimmt, muss an dieser Stelle die Matrix der quadratischen Form des Differentials zweiter Ordnung für die Funktion vorliegen ![]() war eindeutig positiv. Zeigen wir es.
war eindeutig positiv. Zeigen wir es.
Das Differential zweiter Ordnung hat die Form: 
Also
Daher hat die Matrix quadratischer Form die Form 
und die Werte der Elemente hängen nicht davon ab A Und B.
Zeigen wir, dass die Matrix positiv definit ist. Dazu müssen die eckigen Nebenwerte positiv sein.
Winkelmoll erster Ordnung  . Die Ungleichung ist streng, da die Punkte nicht übereinstimmen. Im Folgenden werden wir dies andeuten.
. Die Ungleichung ist streng, da die Punkte nicht übereinstimmen. Im Folgenden werden wir dies andeuten.
Winkelmoll zweiter Ordnung 
Lasst uns das beweisen  nach der Methode der mathematischen Induktion.
nach der Methode der mathematischen Induktion.

Abschluss: Werte gefunden A Und B entsprechen dem kleinsten Wert der Funktion ![]() sind daher die erforderlichen Parameter für die Methode der kleinsten Quadrate.
sind daher die erforderlichen Parameter für die Methode der kleinsten Quadrate.
Keine Zeit, es herauszufinden?
Bestellen Sie eine Lösung
Seitenanfang
Erstellen einer Prognose mithilfe der Methode der kleinsten Quadrate. Beispiel einer Problemlösung
Extrapolation ist eine wissenschaftliche Forschungsmethode, die auf der Verbreitung vergangener und gegenwärtiger Trends, Muster und Zusammenhänge mit der zukünftigen Entwicklung des Prognoseobjekts basiert. Zu den Extrapolationsmethoden gehören Methode des gleitenden Durchschnitts, Methode der exponentiellen Glättung, Methode der kleinsten Quadrate.
Wesen Methode der kleinsten Quadrate besteht darin, die Summe der quadratischen Abweichungen zwischen beobachteten und berechneten Werten zu minimieren. Die berechneten Werte werden anhand der ausgewählten Gleichung – der Regressionsgleichung – ermittelt. Je geringer der Abstand zwischen den tatsächlichen Werten und den berechneten ist, desto genauer ist die Prognose auf Basis der Regressionsgleichung.
Als Grundlage für die Auswahl einer Kurve dient eine theoretische Analyse des Wesens des untersuchten Phänomens, dessen Veränderung sich in einer Zeitreihe widerspiegelt. Manchmal werden Überlegungen zur Art des Anstiegs der Reihenniveaus berücksichtigt. Wenn also ein Produktionswachstum in einer arithmetischen Folge erwartet wird, erfolgt die Glättung in einer geraden Linie. Wenn sich herausstellt, dass das Wachstum geometrisch fortschreitet, muss eine Glättung mithilfe einer Exponentialfunktion erfolgen.
Arbeitsformel für die Methode der kleinsten Quadrate : Y t+1 = a*X + b, wobei t + 1 – Prognosezeitraum; Уt+1 – vorhergesagter Indikator; a und b sind Koeffizienten; X ist ein Symbol der Zeit.
Die Berechnung der Koeffizienten a und b erfolgt nach folgenden Formeln:
 |
 |
wo, Uf – tatsächliche Werte der Dynamikreihe; n – Anzahl der Zeitreihenebenen;
Die Glättung von Zeitreihen mithilfe der Methode der kleinsten Quadrate dient dazu, das Entwicklungsmuster des untersuchten Phänomens widerzuspiegeln. Bei der analytischen Darstellung eines Trends wird die Zeit als unabhängige Variable betrachtet und die Niveaus der Reihe fungieren als Funktion dieser unabhängigen Variablen.
Die Entwicklung eines Phänomens hängt nicht davon ab, wie viele Jahre seit seinem Beginn vergangen sind, sondern davon, welche Faktoren seine Entwicklung in welche Richtung und mit welcher Intensität beeinflusst haben. Daraus wird deutlich, dass die Entwicklung eines Phänomens im Laufe der Zeit das Ergebnis der Wirkung dieser Faktoren ist.
Die korrekte Bestimmung des Kurventyps und der Art der analytischen Abhängigkeit von der Zeit ist eine der schwierigsten Aufgaben der prädiktiven Analyse .
Die Auswahl des Typs der den Trend beschreibenden Funktion, deren Parameter nach der Methode der kleinsten Quadrate bestimmt werden, erfolgt in den meisten Fällen empirisch, indem eine Reihe von Funktionen konstruiert und entsprechend dem Wert der Funktion miteinander verglichen werden mittlerer quadratischer Fehler, berechnet nach der Formel:
 |
wobei UV die tatsächlichen Werte der Dynamikreihe sind; Ur – berechnete (geglättete) Werte der Dynamikreihe; n – Anzahl der Zeitreihenebenen; p – die Anzahl der Parameter, die in Formeln definiert sind, die den Trend (Entwicklungstrend) beschreiben.
Nachteile der Methode der kleinsten Quadrate :
- Wenn versucht wird, das untersuchte Wirtschaftsphänomen mithilfe einer mathematischen Gleichung zu beschreiben, ist die Prognose für einen kurzen Zeitraum genau und die Regressionsgleichung sollte neu berechnet werden, sobald neue Informationen verfügbar sind.
- die Komplexität der Auswahl einer Regressionsgleichung, die mit Standard-Computerprogrammen lösbar ist.
Ein Beispiel für die Verwendung der Methode der kleinsten Quadrate zur Entwicklung einer Prognose
Aufgabe . Es liegen Daten vor, die die Arbeitslosenquote in der Region charakterisieren, %
- Erstellen Sie eine Prognose der Arbeitslosenquote in der Region für November, Dezember und Januar unter Verwendung der folgenden Methoden: gleitender Durchschnitt, exponentielle Glättung, kleinste Quadrate.
- Berechnen Sie die Fehler in den resultierenden Prognosen mit jeder Methode.
- Vergleichen Sie die Ergebnisse und ziehen Sie Schlussfolgerungen.
Lösung der kleinsten Quadrate
Um dieses Problem zu lösen, erstellen wir eine Tabelle, in der wir die notwendigen Berechnungen durchführen:
ε = 28,63/10 = 2,86 % Prognosegenauigkeit hoch.
Abschluss : Vergleich der Ergebnisse der Berechnungen Methode des gleitenden Durchschnitts , exponentielle Glättungsmethode und der Methode der kleinsten Quadrate können wir sagen, dass der durchschnittliche relative Fehler bei der Berechnung mit der Methode der exponentiellen Glättung im Bereich von 20–50 % liegt. Das bedeutet, dass die Genauigkeit der Prognose in diesem Fall nur zufriedenstellend ist.
Im ersten und dritten Fall ist die Prognosegenauigkeit hoch, da der durchschnittliche relative Fehler weniger als 10 % beträgt. Die Methode des gleitenden Durchschnitts ermöglichte es jedoch, zuverlässigere Ergebnisse zu erhalten (Prognose für November – 1,52 %, Prognose für Dezember – 1,53 %, Prognose für Januar – 1,49 %), da der durchschnittliche relative Fehler bei Verwendung dieser Methode am kleinsten ist – 1 ,13 %.
Methode der kleinsten Quadrate
Weitere Artikel zu diesem Thema:
Liste der verwendeten Quellen
- Wissenschaftliche und methodische Empfehlungen zur Diagnose gesellschaftlicher Risiken und zur Prognose von Herausforderungen, Bedrohungen und gesellschaftlichen Folgen. Russische Staatliche Sozialuniversität. Moskau. 2010;
- Vladimirova L.P. Prognose und Planung unter Marktbedingungen: Lehrbuch. Zuschuss. M.: Verlag „Dashkov and Co“, 2001;
- Novikova N.V., Pozdeeva O.G. Prognose der Volkswirtschaft: Lehr- und Methodenhandbuch. Jekaterinburg: Ural-Verlag. Zustand ökon. Univ., 2007;
- Slutskin L.N. MBA-Kurs zum Thema Geschäftsprognose. M.: Alpina Business Books, 2006.
MNC-Programm
Daten eingeben
Daten und Näherung y = a + b x
ich- Anzahl der Versuchspunkte;
x i- Wert eines festen Parameters an einem Punkt ich;
y i- Wert des gemessenen Parameters an einem Punkt ich;
ωi- Gewicht an einem Punkt messen ich;
y i, kalk.- Differenz zwischen gemessenem und regressionsberechnetem Wert j am Punkt ich;
S x i (x i)- Fehlerschätzung x i beim Messen j am Punkt ich.
Daten und Näherung y = k x
| ich | x i | y i | ωi | y i, kalk. | Δy ich | S x i (x i) |
|---|
Klicken Sie auf das Diagramm
Benutzerhandbuch für das MNC-Onlineprogramm.
Geben Sie im Datenfeld in jeder einzelnen Zeile die Werte von „x“ und „y“ an einem experimentellen Punkt ein. Werte müssen durch ein Leerzeichen (Leerzeichen oder Tabulator) getrennt werden.
Der dritte Wert könnte das Gewicht des Punktes „w“ sein. Wenn das Gewicht eines Punktes nicht angegeben ist, ist es gleich eins. In den allermeisten Fällen sind die Gewichte der experimentellen Punkte unbekannt oder werden nicht berechnet, d. h. Alle experimentellen Daten gelten als gleichwertig. Manchmal sind die Gewichte im untersuchten Wertebereich absolut nicht gleichwertig und lassen sich sogar theoretisch berechnen. Beispielsweise können in der Spektrophotometrie Gewichte mit einfachen Formeln berechnet werden, obwohl dies aus Gründen der Arbeitskostenreduzierung meist vernachlässigt wird.
Daten können über die Zwischenablage aus einer Tabellenkalkulation in einer Office-Suite wie Excel von Microsoft Office oder Calc von Open Office eingefügt werden. Wählen Sie dazu in der Tabelle den zu kopierenden Datenbereich aus, kopieren Sie ihn in die Zwischenablage und fügen Sie die Daten in das Datenfeld auf dieser Seite ein.
Um mit der Methode der kleinsten Quadrate zu berechnen, sind mindestens zwei Punkte erforderlich, um zwei Koeffizienten „b“ – den Tangens des Neigungswinkels der Linie – und „a“ – den Wert, der von der Linie auf der „y“-Achse geschnitten wird, zu bestimmen.
Um den Fehler der berechneten Regressionskoeffizienten abzuschätzen, müssen Sie die Anzahl der experimentellen Punkte auf mehr als zwei festlegen.
Methode der kleinsten Quadrate (LSM).
Je größer die Anzahl der Versuchspunkte, desto genauer ist die statistische Bewertung der Koeffizienten (aufgrund einer Abnahme des Student-Koeffizienten) und desto näher kommt die Schätzung der Schätzung der Gesamtstichprobe.
Die Ermittlung von Werten an jedem Versuchspunkt ist oft mit erheblichen Arbeitskosten verbunden, daher wird oft eine Kompromisszahl von Experimenten durchgeführt, die eine überschaubare Schätzung liefert und nicht zu übermäßigen Arbeitskosten führt. In der Regel wird die Anzahl der experimentellen Punkte für eine lineare Abhängigkeit der kleinsten Quadrate mit zwei Koeffizienten im Bereich von 5–7 Punkten gewählt.
Eine kurze Theorie der kleinsten Quadrate für lineare Beziehungen
Nehmen wir an, wir haben einen Satz experimenteller Daten in Form von Wertepaaren [`y_i`, `x_i`], wobei `i` die Nummer einer experimentellen Messung von 1 bis `n` ist; „y_i“ – der Wert der gemessenen Größe am Punkt „i“; „x_i“ – der Wert des Parameters, den wir am Punkt „i“ festlegen.
Betrachten Sie als Beispiel die Wirkungsweise des Ohmschen Gesetzes. Indem wir die Spannung (Potenzialdifferenz) zwischen Abschnitten eines Stromkreises ändern, messen wir die Strommenge, die durch diesen Abschnitt fließt. Die Physik gibt uns eine experimentell gefundene Abhängigkeit:
„I = U/R“,
wobei „Ich“ die aktuelle Stärke ist; „R“ – Widerstand; „U“ – Spannung.
In diesem Fall ist „y_i“ der gemessene Stromwert und „x_i“ der Spannungswert.
Betrachten Sie als weiteres Beispiel die Absorption von Licht durch eine Lösung einer Substanz in Lösung. Die Chemie gibt uns die Formel:
`A = ε l C`,
wobei „A“ die optische Dichte der Lösung ist; „ε“ – Durchlässigkeit des gelösten Stoffes; „l“ – Weglänge, wenn Licht durch eine Küvette mit einer Lösung geht; „C“ ist die Konzentration des gelösten Stoffes.
In diesem Fall ist „y_i“ der gemessene Wert der optischen Dichte „A“ und „x_i“ der Konzentrationswert der von uns angegebenen Substanz.
Wir betrachten den Fall, wenn der relative Fehler in der Zuweisung „x_i“ deutlich kleiner ist als der relative Fehler in der Messung „y_i“. Wir gehen außerdem davon aus, dass alle gemessenen Werte „y_i“ zufällig und normalverteilt sind, d. h. gehorchen dem Normalverteilungsgesetz.
Im Fall einer linearen Abhängigkeit von „y“ von „x“ können wir die theoretische Abhängigkeit schreiben:
`y = a + b x`.
Aus geometrischer Sicht bezeichnet der Koeffizient „b“ den Tangens des Neigungswinkels der Linie zur „x“-Achse und der Koeffizient „a“ den Wert von „y“ am Schnittpunkt der Linie mit der „y“-Achse (bei „x = 0“).
Ermitteln der Parameter der Regressionslinie.
In einem Experiment können die Messwerte von „y_i“ aufgrund von Messfehlern, die im wirklichen Leben immer inhärent sind, nicht genau auf der theoretischen Geraden liegen. Daher muss eine lineare Gleichung durch ein Gleichungssystem dargestellt werden:
`y_i = a + b x_i + ε_i` (1),
wobei „ε_i“ der unbekannte Messfehler von „y“ im „i“-ten Experiment ist.
Abhängigkeit (1) wird auch aufgerufen Rückschritt, d.h. die Abhängigkeit zweier Größen voneinander mit statistischer Signifikanz.
Die Aufgabe der Wiederherstellung der Abhängigkeit besteht darin, die Koeffizienten „a“ und „b“ aus den experimentellen Punkten [„y_i“, „x_i““ zu finden.
Um die Koeffizienten „a“ und „b“ zu finden, wird es normalerweise verwendet Methode der kleinsten Quadrate(MNC). Es handelt sich um einen Sonderfall des Maximum-Likelihood-Prinzips.
Schreiben wir (1) in der Form „ε_i = y_i – a – b x_i“ um.
Dann beträgt die Summe der quadrierten Fehler
`Φ = sum_(i=1)^(n) ε_i^2 = sum_(i=1)^(n) (y_i - a - b x_i)^2`. (2)
Das Prinzip der kleinsten Quadrate (kleinste Quadrate) besteht darin, die Summe (2) in Bezug auf die Parameter „a“ und „b“ zu minimieren.
Das Minimum wird erreicht, wenn die partiellen Ableitungen der Summe (2) nach den Koeffizienten „a“ und „b“ gleich Null sind:
`frac(partielles Φ)(partielles a) = frac(partielle Summe_(i=1)^(n) (y_i - a - b x_i)^2)(partielles a) = 0`
`frac(partielles Φ)(partielles b) = frac(partielle Summe_(i=1)^(n) (y_i - a - b x_i)^2)(partielles b) = 0`
Wenn wir die Ableitungen erweitern, erhalten wir ein System aus zwei Gleichungen mit zwei Unbekannten:
`sum_(i=1)^(n) (2a + 2bx_i — 2y_i) = sum_(i=1)^(n) (a + bx_i — y_i) = 0`
`sum_(i=1)^(n) (2bx_i^2 + 2ax_i — 2x_iy_i) = sum_(i=1)^(n) (bx_i^2 + ax_i — x_iy_i) = 0`
Wir öffnen die Klammern und übertragen die Summen unabhängig von den geforderten Koeffizienten auf die andere Hälfte, wir erhalten ein System linearer Gleichungen:
`sum_(i=1)^(n) y_i = a n + b sum_(i=1)^(n) bx_i`
`sum_(i=1)^(n) x_iy_i = a sum_(i=1)^(n) x_i + b sum_(i=1)^(n) x_i^2`
Wenn wir das resultierende System lösen, finden wir Formeln für die Koeffizienten „a“ und „b“:
`a = frac(sum_(i=1)^(n) y_i sum_(i=1)^(n) x_i^2 — sum_(i=1)^(n) x_i sum_(i=1)^(n ) x_iy_i) (n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2)` (3.1)
`b = frac(n sum_(i=1)^(n) x_iy_i — sum_(i=1)^(n) x_i sum_(i=1)^(n) y_i) (n sum_(i=1)^ (n) x_i^2 — (sum_(i=1)^(n) x_i)^2)` (3.2)
Diese Formeln haben Lösungen, wenn „n > 1“ (die Linie kann aus mindestens 2 Punkten konstruiert werden) und wenn die Determinante „D = n sum_(i=1)^(n) x_i^2 – (sum_(i= 1 )^(n) x_i)^2 != 0`, d.h. wenn die „x_i“-Punkte im Experiment unterschiedlich sind (d. h. wenn die Linie nicht vertikal ist).
Schätzung der Fehler der Regressionslinienkoeffizienten
Für eine genauere Beurteilung des Fehlers bei der Berechnung der Koeffizienten „a“ und „b“ ist eine große Anzahl experimenteller Punkte wünschenswert. Bei „n = 2“ ist es unmöglich, den Fehler der Koeffizienten abzuschätzen, weil Die Näherungslinie verläuft eindeutig durch zwei Punkte.
Der Fehler der Zufallsvariablen „V“ wird bestimmt Gesetz der Fehlerakkumulation
`S_V^2 = sum_(i=1)^p (frac(partielles f)(partielles z_i))^2 S_(z_i)^2`,
wobei „p“ die Anzahl der Parameter „z_i“ mit Fehler „S_(z_i)“ ist, die sich auf den Fehler „S_V“ auswirken;
„f“ ist eine Funktion der Abhängigkeit von „V“ von „z_i“.
Schreiben wir das Gesetz der Fehlerakkumulation für den Fehler der Koeffizienten „a“ und „b“ auf
`S_a^2 = sum_(i=1)^(n)(frac(partial a)(partial y_i))^2 S_(y_i)^2 + sum_(i=1)^(n)(frac(partial a )(partielles x_i))^2 S_(x_i)^2 = S_y^2 sum_(i=1)^(n)(frac(partielles a)(partielles y_i))^2 `,
`S_b^2 = sum_(i=1)^(n)(frac(partial b)(partial y_i))^2 S_(y_i)^2 + sum_(i=1)^(n)(frac(partial b )(partielles x_i))^2 S_(x_i)^2 = S_y^2 sum_(i=1)^(n)(frac(partielles b)(partielles y_i))^2 `,
Weil „S_(x_i)^2 = 0“ (wir haben zuvor einen Vorbehalt gemacht, dass der Fehler „x“ vernachlässigbar ist).
„S_y^2 = S_(y_i)^2“ – Fehler (Varianz, quadratische Standardabweichung) bei der Messung von „y“, unter der Annahme, dass der Fehler für alle Werte von „y“ einheitlich ist.
Wenn wir die Formeln zur Berechnung von „a“ und „b“ in die resultierenden Ausdrücke einsetzen, erhalten wir
`S_a^2 = S_y^2 frac(sum_(i=1)^(n) (sum_(i=1)^(n) x_i^2 — x_i sum_(i=1)^(n) x_i)^2 ) (D^2) = S_y^2 frac((n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2) sum_(i=1) ^(n) x_i^2) (D^2) = S_y^2 frac(sum_(i=1)^(n) x_i^2) (D)` (4.1)
`S_b^2 = S_y^2 frac(sum_(i=1)^(n) (n x_i — sum_(i=1)^(n) x_i)^2) (D^2) = S_y^2 frac( n (n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2)) (D^2) = S_y^2 frac(n) (D) ` (4.2)
In den meisten realen Experimenten wird der Wert von „Sy“ nicht gemessen. Hierzu ist es notwendig, mehrere parallele Messungen (Experimente) an einem oder mehreren Punkten im Plan durchzuführen, was die Zeit (und möglicherweise auch die Kosten) des Experiments erhöht. Daher wird üblicherweise angenommen, dass die Abweichung von „y“ von der Regressionsgeraden als zufällig angesehen werden kann. Die Schätzung der Varianz „y“ wird in diesem Fall anhand der Formel berechnet.
„S_y^2 = S_(y, rest)^2 = frac(sum_(i=1)^n (y_i – a – b x_i)^2) (n-2)“.
Der „n-2“-Teiler erscheint, weil unsere Anzahl an Freiheitsgraden aufgrund der Berechnung von zwei Koeffizienten unter Verwendung derselben Stichprobe experimenteller Daten abgenommen hat.
Diese Schätzung wird auch als Restvarianz relativ zur Regressionslinie „S_(y, rest)^2“ bezeichnet.
Die Signifikanz der Koeffizienten wird mithilfe des Student-t-Tests bewertet
`t_a = frac(|a|) (S_a)`, `t_b = frac(|b|) (S_b)`
Wenn die berechneten Kriterien „t_a“, „t_b“ kleiner sind als die tabellierten Kriterien „t(P, n-2)“, dann wird davon ausgegangen, dass der entsprechende Koeffizient mit einer gegebenen Wahrscheinlichkeit „P“ nicht signifikant von Null abweicht.
Um die Qualität der Beschreibung einer linearen Beziehung zu beurteilen, können Sie „S_(y, rest)^2“ und „S_(bar y)“ relativ zum Mittelwert mithilfe des Fisher-Kriteriums vergleichen.
`S_(bar y) = frac(sum_(i=1)^n (y_i — bar y)^2) (n-1) = frac(sum_(i=1)^n (y_i — (sum_(i= 1)^n y_i) /n)^2) (n-1)` – Stichprobenschätzung der Varianz „y“ relativ zum Mittelwert.
Um die Wirksamkeit der Regressionsgleichung zur Beschreibung der Abhängigkeit zu beurteilen, wird der Fisher-Koeffizient berechnet
`F = S_(bar y) / S_(y, rest)^2`,
der mit dem tabellarischen Fisher-Koeffizienten „F(p, n-1, n-2)“ verglichen wird.
Wenn „F > F(P, n-1, n-2)“, wird der Unterschied zwischen der Beschreibung der Beziehung „y = f(x)“ mithilfe der Regressionsgleichung und der Beschreibung mithilfe des Mittelwerts mit Wahrscheinlichkeit als statistisch signifikant angesehen „P“. Diese. Die Regression beschreibt die Abhängigkeit besser als die Streuung von „y“ um den Mittelwert.
Klicken Sie auf das Diagramm
um Werte zur Tabelle hinzuzufügen
Methode der kleinsten Quadrate. Die Methode der kleinsten Quadrate bedeutet die Bestimmung unbekannter Parameter a, b, c, der akzeptierten funktionalen Abhängigkeit
Die Methode der kleinsten Quadrate bezieht sich auf die Bestimmung unbekannter Parameter a, b, c,… akzeptierte funktionale Abhängigkeit
y = f(x,a,b,c,…),
was ein Minimum des mittleren Quadrats (Varianz) des Fehlers liefern würde
 , (24)
, (24)
wobei x i, y i eine Menge von Zahlenpaaren ist, die aus dem Experiment erhalten wurden.
Da die Bedingung für das Extremum einer Funktion mehrerer Variablen die Bedingung ist, dass ihre partiellen Ableitungen gleich Null sind, dann sind die Parameter a, b, c,… werden aus dem Gleichungssystem ermittelt:
; ; ; … (25)
Es muss beachtet werden, dass die Methode der kleinsten Quadrate verwendet wird, um Parameter nach dem Funktionstyp auszuwählen y = f(x) definiert
Wenn aus theoretischen Überlegungen keine Rückschlüsse auf die empirische Formel gezogen werden können, muss man sich an visuellen Darstellungen orientieren, vor allem an grafischen Darstellungen der beobachteten Daten.
In der Praxis beschränken sie sich meist auf die folgenden Funktionstypen:
1) linear ![]() ;
;
2) quadratisch a.
100 RUR Bonus für die erste Bestellung
Wählen Sie die Art der Arbeit aus. Diplomarbeit. Kursarbeit. Zusammenfassung. Masterarbeit. Praxisbericht. Artikel. Bericht. Rezension. Testarbeit. Monographie. Problemlösung. Geschäftsplan. Antworten auf Fragen. Kreative Arbeit. Aufsatz. Zeichnen. Essays. Übersetzung. Präsentationen. Tippen. Sonstiges. Erhöhung der Einzigartigkeit des Textes. Masterarbeit. Laborarbeit. Online-Hilfe
Finden Sie den Preis heraus
Die Methode der kleinsten Quadrate ist eine mathematische (mathematisch-statistische) Technik, die dazu dient, Zeitreihen auszurichten, die Form der Korrelation zwischen Zufallsvariablen zu identifizieren usw. Sie besteht darin, dass die Funktion, die ein bestimmtes Phänomen beschreibt, durch eine einfachere Funktion angenähert wird. Letzteres wird zudem so gewählt, dass die Standardabweichung (siehe Streuung) der tatsächlichen Niveaus der Funktion an den beobachteten Punkten von den ausgerichteten am kleinsten ist.
Den verfügbaren Daten zufolge ( xi,yi) (ich = 1, 2, ..., N) wird eine solche Kurve konstruiert j = A + bx, bei dem die minimale Summe der quadratischen Abweichungen erreicht wird
d.h. eine von zwei Parametern abhängige Funktion wird minimiert: A- Segment auf der Ordinatenachse und B- Gerade Steigung.
Gleichungen, die die notwendigen Bedingungen zur Minimierung der Funktion angeben S(A,B), werden genannt normale Gleichungen. Als Näherungsfunktionen werden nicht nur linear (Ausrichtung entlang einer Geraden), sondern auch quadratisch, parabolisch, exponentiell usw. verwendet. Ein Beispiel für die Ausrichtung einer Zeitreihe entlang einer Geraden finden Sie in Abb. M.2, wobei die Summe der quadrierten Abstände ( j 1 – ȳ 1)2 + (j 2 – ȳ 2)2 .... ist der kleinste, und die resultierende gerade Linie spiegelt am besten den Trend einer dynamischen Reihe von Beobachtungen eines bestimmten Indikators über die Zeit wider.
Für unverzerrte OLS-Schätzungen ist es notwendig und ausreichend, die wichtigste Bedingung der Regressionsanalyse zu erfüllen: Die mathematische Erwartung eines zufälligen Fehlers, bedingt durch die Faktoren, muss gleich Null sein. Diese Bedingung ist insbesondere dann erfüllt, wenn: 1. die mathematische Erwartung von Zufallsfehlern Null ist und 2. Faktoren und Zufallsfehler unabhängige Zufallsvariablen sind. Die erste Bedingung kann für Modelle mit einer Konstante als immer erfüllt angesehen werden, da die Konstante eine mathematische Fehlererwartung ungleich Null annimmt. Die zweite Bedingung – die Bedingung der Exogenität der Faktoren – ist grundlegend. Wenn diese Eigenschaft nicht erfüllt ist, können wir davon ausgehen, dass fast alle Schätzungen äußerst unbefriedigend sind: Sie sind nicht einmal konsistent (d. h. selbst eine sehr große Datenmenge ermöglicht es uns in diesem Fall nicht, qualitativ hochwertige Schätzungen zu erhalten ).
Die gebräuchlichste Methode zur statistischen Schätzung von Parametern von Regressionsgleichungen ist die Methode der kleinsten Quadrate. Diese Methode basiert auf einer Reihe von Annahmen hinsichtlich der Art der Daten und der Ergebnisse des Modells. Die wichtigsten sind eine klare Unterteilung der ursprünglichen Variablen in abhängige und unabhängige, die Nichtkorrelation der in den Gleichungen enthaltenen Faktoren, die Linearität der Beziehung, das Fehlen einer Autokorrelation der Residuen, die Gleichheit ihrer mathematischen Erwartungen mit Null und Konstante Streuung.
Eine der Haupthypothesen von OLS ist die Annahme der Gleichheit der Varianzen der Abweichungen ei, d.h. ihre Spanne um den Durchschnittswert (Null) der Reihe sollte einen stabilen Wert haben. Diese Eigenschaft wird Homoskedastizität genannt. In der Praxis sind die Varianzen der Abweichungen häufig ungleich, das heißt, es wird Heteroskedastizität beobachtet. Dies kann verschiedene Gründe haben. Beispielsweise können Fehler in den Quelldaten vorliegen. Gelegentliche Ungenauigkeiten in den Quellinformationen, beispielsweise Fehler in der Reihenfolge der Zahlen, können erhebliche Auswirkungen auf die Ergebnisse haben. Bei großen Werten der abhängigen Variablen (Variablen) wird häufig eine größere Streuung der Abweichungen єi beobachtet. Wenn die Daten einen erheblichen Fehler enthalten, ist natürlich auch die Abweichung des aus den fehlerhaften Daten berechneten Modellwerts groß. Um diesen Fehler zu beseitigen, müssen wir den Beitrag dieser Daten zu den Berechnungsergebnissen reduzieren und ihnen weniger Gewicht zuweisen als allen anderen. Diese Idee wird im gewichteten OLS umgesetzt.
Methode der kleinsten Quadrate
Methode der kleinsten Quadrate ( OLS, OLS, gewöhnliche kleinste Quadrate) - eine der grundlegenden Methoden der Regressionsanalyse zur Schätzung unbekannter Parameter von Regressionsmodellen anhand von Beispieldaten. Die Methode basiert auf der Minimierung der Summe der Quadrate der Regressionsresiduen.
Es ist zu beachten, dass die Methode der kleinsten Quadrate selbst als Methode zur Lösung eines Problems in einem beliebigen Bereich bezeichnet werden kann, wenn die Lösung in einem Kriterium zur Minimierung der Quadratsumme einiger Funktionen der erforderlichen Variablen liegt oder dieses erfüllt. Daher kann die Methode der kleinsten Quadrate auch für eine ungefähre Darstellung (Approximation) einer bestimmten Funktion durch andere (einfachere) Funktionen verwendet werden, wenn eine Menge von Größen gefunden wird, die Gleichungen oder Einschränkungen erfüllen, deren Anzahl die Anzahl dieser Größen übersteigt , usw.
Die Essenz von MNC
Gegeben sei ein (parametrisches) Modell einer probabilistischen (Regressions-)Beziehung zwischen der (erklärten) Variablen j und viele Faktoren (erklärende Variablen) X
Wo ist der Vektor unbekannter Modellparameter?
- Zufälliger Modellfehler.Lassen Sie es auch Beispielbeobachtungen der Werte dieser Variablen geben. Sei die Beobachtungszahl (). Dann sind die Werte der Variablen in der Beobachtung. Dann ist es für gegebene Werte der Parameter b möglich, die theoretischen (Modell-)Werte der erklärten Variablen y zu berechnen:
Die Größe der Residuen hängt von den Werten der Parameter b ab.
Das Wesen der Methode der kleinsten Quadrate (gewöhnlich, klassisch) besteht darin, Parameter b zu finden, für die die Summe der Quadrate der Residuen (eng. Restquadratsumme) wird minimal sein:
Im Allgemeinen kann dieses Problem durch numerische Optimierungs- (Minimierungs-)Methoden gelöst werden. In diesem Fall reden sie darüber nichtlineare kleinste Quadrate(NLS oder NLS – Englisch) Nichtlineare kleinste Quadrate). In vielen Fällen ist es möglich, eine analytische Lösung zu erhalten. Um das Minimierungsproblem zu lösen, ist es notwendig, stationäre Punkte der Funktion zu finden, indem man sie nach den unbekannten Parametern b differenziert, die Ableitungen mit Null gleichsetzt und das resultierende Gleichungssystem löst:
Wenn die Zufallsfehler des Modells normalverteilt sind, die gleiche Varianz aufweisen und unkorreliert sind, sind die OLS-Parameterschätzungen dieselben wie die Maximum-Likelihood-Schätzungen (MLM).
OLS im Fall eines linearen Modells
Die Regressionsabhängigkeit sei linear:
Lassen j ist ein Spaltenvektor von Beobachtungen der erklärten Variablen und eine Matrix von Faktorbeobachtungen (die Zeilen der Matrix sind die Vektoren der Faktorwerte in einer bestimmten Beobachtung, die Spalten sind der Vektor der Werte eines bestimmten Faktors in allen Beobachtungen). Die Matrixdarstellung des linearen Modells lautet:
Dann sind der Vektor der Schätzungen der erklärten Variablen und der Vektor der Regressionsresiduen gleich
Dementsprechend ist die Summe der Quadrate der Regressionsresiduen gleich
Wenn wir diese Funktion nach dem Parametervektor differenzieren und die Ableitungen mit Null gleichsetzen, erhalten wir ein Gleichungssystem (in Matrixform):
.Die Lösung dieses Gleichungssystems ergibt die allgemeine Formel für Schätzungen der kleinsten Quadrate für ein lineares Modell:
Für analytische Zwecke ist die letztere Darstellung dieser Formel nützlich. Wenn in einem Regressionsmodell die Daten zentriert, dann hat in dieser Darstellung die erste Matrix die Bedeutung einer Stichproben-Kovarianzmatrix von Faktoren und die zweite ist ein Vektor von Kovarianzen von Faktoren mit der abhängigen Variablen. Wenn zusätzlich die Daten auch sind normalisiert zu MSE (das heißt letztendlich standardisiert), dann hat die erste Matrix die Bedeutung einer Stichprobenkorrelationsmatrix von Faktoren, der zweite Vektor - ein Vektor von Stichprobenkorrelationen von Faktoren mit der abhängigen Variablen.
Eine wichtige Eigenschaft von OLS-Schätzungen für Modelle mit Konstante- Die Linie der konstruierten Regression verläuft durch den Schwerpunkt der Stichprobendaten, d. h. die Gleichheit ist erfüllt:
Insbesondere im Extremfall, wenn der einzige Regressor eine Konstante ist, stellen wir fest, dass die OLS-Schätzung des einzigen Parameters (der Konstante selbst) gleich dem Durchschnittswert der erklärten Variablen ist. Das heißt, das arithmetische Mittel, das für seine guten Eigenschaften aus den Gesetzen der großen Zahlen bekannt ist, ist auch eine Schätzung der kleinsten Quadrate – es erfüllt das Kriterium der minimalen Summe der quadratischen Abweichungen davon.
Beispiel: einfachste (paarweise) Regression
Bei der gepaarten linearen Regression werden die Berechnungsformeln vereinfacht (Sie können auf Matrixalgebra verzichten):
Eigenschaften von OLS-Schätzern
Zunächst stellen wir fest, dass es sich bei den OLS-Schätzungen für lineare Modelle um lineare Schätzungen handelt, wie aus der obigen Formel hervorgeht. Für unverzerrte OLS-Schätzungen ist es notwendig und ausreichend, die wichtigste Bedingung der Regressionsanalyse zu erfüllen: Die mathematische Erwartung eines zufälligen Fehlers, bedingt durch die Faktoren, muss gleich Null sein. Diese Bedingung ist insbesondere dann erfüllt, wenn
- die mathematische Erwartung zufälliger Fehler ist Null und
- Faktoren und Zufallsfehler sind unabhängige Zufallsvariablen.
Die zweite Bedingung – die Bedingung der Exogenität der Faktoren – ist grundlegend. Wenn diese Eigenschaft nicht erfüllt ist, können wir davon ausgehen, dass fast alle Schätzungen äußerst unbefriedigend sind: Sie sind nicht einmal konsistent (d. h. selbst eine sehr große Datenmenge ermöglicht es uns in diesem Fall nicht, qualitativ hochwertige Schätzungen zu erhalten ). Im klassischen Fall wird im Gegensatz zu einem Zufallsfehler eine stärkere Annahme über den Determinismus der Faktoren getroffen, was automatisch bedeutet, dass die Exogenitätsbedingung erfüllt ist. Im allgemeinen Fall reicht es für die Konsistenz der Schätzungen aus, die Exogenitätsbedingung zusammen mit der Konvergenz der Matrix zu einer nicht singulären Matrix zu erfüllen, wenn die Stichprobengröße bis ins Unendliche ansteigt.
Damit Schätzungen der (gewöhnlichen) kleinsten Quadrate neben Konsistenz und Unvoreingenommenheit auch effektiv sind (die besten in der Klasse der linearen unvoreingenommenen Schätzungen), müssen zusätzliche Eigenschaften des Zufallsfehlers erfüllt sein:
Diese Annahmen können für die Kovarianzmatrix des Zufallsfehlervektors formuliert werden
Ein lineares Modell, das diese Bedingungen erfüllt, heißt klassisch. OLS-Schätzungen für die klassische lineare Regression sind erwartungstreue, konsistente und die effektivsten Schätzungen in der Klasse aller linearen erwartungstreuen Schätzungen (in der englischen Literatur wird die Abkürzung manchmal verwendet). BLAU (Bester linearer, unvermittelter Schätzer) – die beste lineare unverzerrte Schätzung; in der russischen Literatur wird häufiger das Gauß-Markov-Theorem zitiert). Wie leicht zu zeigen ist, ist die Kovarianzmatrix des Vektors der Koeffizientenschätzungen gleich:
Generalisiertes OLS
Die Methode der kleinsten Quadrate ermöglicht eine breite Verallgemeinerung. Anstatt die Summe der Quadrate der Residuen zu minimieren, kann man eine positiv definite quadratische Form des Residuenvektors minimieren, bei der es sich um eine symmetrische positiv definite Gewichtsmatrix handelt. Ein Sonderfall dieses Ansatzes ist die konventionelle Methode der kleinsten Quadrate, bei der die Gewichtsmatrix proportional zur Identitätsmatrix ist. Wie aus der Theorie der symmetrischen Matrizen (oder Operatoren) bekannt ist, gibt es für solche Matrizen eine Zerlegung. Folglich kann das angegebene Funktional wie folgt dargestellt werden, das heißt, dieses Funktional kann als Summe der Quadrate einiger transformierter „Reste“ dargestellt werden. Somit können wir eine Klasse von Methoden der kleinsten Quadrate unterscheiden – LS-Methoden (Least Squares).
Es wurde bewiesen (Theorem von Aitken), dass für ein verallgemeinertes lineares Regressionsmodell (bei dem keine Einschränkungen für die Kovarianzmatrix zufälliger Fehler gelten) die sogenannten Schätzungen am effektivsten (in der Klasse der linearen unverzerrten Schätzungen) sind. verallgemeinerte kleinste Quadrate (GLS – Generalized Least Squares)- LS-Methode mit einer Gewichtsmatrix, die der inversen Kovarianzmatrix zufälliger Fehler entspricht: .
Es kann gezeigt werden, dass die Formel für GLS-Schätzungen der Parameter eines linearen Modells die Form hat
Die Kovarianzmatrix dieser Schätzungen ist dementsprechend gleich
Tatsächlich liegt das Wesen von OLS in einer bestimmten (linearen) Transformation (P) der Originaldaten und der Anwendung gewöhnlicher OLS auf die transformierten Daten. Der Zweck dieser Transformation besteht darin, dass für die transformierten Daten die Zufallsfehler bereits die klassischen Annahmen erfüllen.
Gewichtetes OLS
Im Fall einer diagonalen Gewichtsmatrix (und damit einer Kovarianzmatrix zufälliger Fehler) haben wir die sogenannten gewichteten kleinsten Quadrate (WLS). In diesem Fall wird die gewichtete Quadratsumme der Modellresiduen minimiert, d. h. jede Beobachtung erhält ein „Gewicht“, das umgekehrt proportional zur Varianz des Zufallsfehlers in dieser Beobachtung ist: . Tatsächlich werden die Daten durch Gewichtung der Beobachtungen transformiert (Dividierung durch einen Betrag, der proportional zur geschätzten Standardabweichung der Zufallsfehler ist), und auf die gewichteten Daten wird gewöhnliches OLS angewendet.
Einige Sonderfälle der Verwendung von MNC in der Praxis
Annäherung der linearen Abhängigkeit
Betrachten wir den Fall, wenn wir als Ergebnis der Untersuchung der Abhängigkeit einer bestimmten skalaren Größe von einer bestimmten skalaren Größe (dies könnte beispielsweise die Abhängigkeit der Spannung von der Stromstärke sein: , wobei ein konstanter Wert ist, der Widerstand von des Leiters) wurden Messungen dieser Größen durchgeführt, wodurch die Werte und die entsprechenden Werte ermittelt wurden. Die Messdaten müssen in einer Tabelle erfasst werden.
Tisch. Messergebnisse.
| Messnr. | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
Die Frage ist: Welcher Wert des Koeffizienten kann gewählt werden, um die Abhängigkeit am besten zu beschreiben? Nach der Methode der kleinsten Quadrate sollte dieser Wert so sein, dass er die Summe der quadrierten Abweichungen der Werte von den Werten darstellt
war minimal
Die Summe der quadratischen Abweichungen hat ein Extremum – ein Minimum, was uns die Verwendung dieser Formel ermöglicht. Lassen Sie uns aus dieser Formel den Wert des Koeffizienten ermitteln. Dazu transformieren wir seine linke Seite wie folgt:
Mit der letzten Formel können wir den Wert des Koeffizienten ermitteln, der für das Problem erforderlich war.
Geschichte
Bis zum Beginn des 19. Jahrhunderts. Wissenschaftler hatten keine bestimmten Regeln zum Lösen eines Gleichungssystems, in dem die Anzahl der Unbekannten geringer ist als die Anzahl der Gleichungen; Bis zu diesem Zeitpunkt wurden private Techniken verwendet, die von der Art der Gleichungen und vom Scharfsinn der Rechner abhingen, und daher kamen verschiedene Rechner, die auf denselben Beobachtungsdaten basierten, zu unterschiedlichen Schlussfolgerungen. Gauß (1795) war der erste, der die Methode verwendete, und Legendre (1805) entdeckte sie unabhängig und veröffentlichte sie unter ihrem modernen Namen (französisch). Methode der geringsten Streitigkeiten ). Laplace bezog die Methode auf die Wahrscheinlichkeitstheorie, und der amerikanische Mathematiker Adrain (1808) befasste sich mit ihren Anwendungen. Die Methode fand weite Verbreitung und wurde durch weitere Forschungen von Encke, Bessel, Hansen und anderen verbessert.
Alternative Verwendungsmöglichkeiten von OLS
Die Idee der Methode der kleinsten Quadrate kann auch in anderen Fällen verwendet werden, die nicht direkt mit der Regressionsanalyse zusammenhängen. Tatsache ist, dass die Quadratsumme eines der gebräuchlichsten Näherungsmaße für Vektoren ist (euklidische Metrik in endlichdimensionalen Räumen).
Eine Anwendung ist die „Lösung“ linearer Gleichungssysteme, bei denen die Anzahl der Gleichungen größer ist als die Anzahl der Variablen
wobei die Matrix nicht quadratisch, sondern rechteckig ist.
Ein solches Gleichungssystem hat im allgemeinen Fall keine Lösung (sofern der Rang tatsächlich größer ist als die Anzahl der Variablen). Daher kann dieses System nur in dem Sinne „gelöst“ werden, dass ein solcher Vektor so gewählt wird, dass der „Abstand“ zwischen den Vektoren und minimiert wird. Dazu können Sie das Kriterium der Minimierung der Quadratsumme der Differenzen zwischen der linken und rechten Seite der Systemgleichungen anwenden. Es lässt sich leicht zeigen, dass die Lösung dieses Minimierungsproblems zur Lösung des folgenden Gleichungssystems führt










