Reichweitenstreuung. Arten von Dispersionen. Standardabweichung der Stichprobe
 .
.
Umgekehrt gilt: if ist ein nicht negativer a.e. Funktion so, dass  , dann gibt es ein absolut stetiges Wahrscheinlichkeitsmaß, so dass es seine Dichte ist.
, dann gibt es ein absolut stetiges Wahrscheinlichkeitsmaß, so dass es seine Dichte ist.
Ersetzen des Maßes im Lebesgue-Integral:
 ,
,
Wo ist eine beliebige Borel-Funktion, die in Bezug auf das Wahrscheinlichkeitsmaß integrierbar ist?
Dispersion, Arten und Eigenschaften der Dispersion Das Konzept der Dispersion
Streuung in der Statistik ergibt sich als Standardabweichung der einzelnen Werte des Merkmals quadriert vom arithmetischen Mittel. Abhängig von den Ausgangsdaten wird sie anhand der einfachen und gewichteten Varianzformeln ermittelt:
1. Einfache Varianz(für nicht gruppierte Daten) wird nach folgender Formel berechnet:
![]()
2. Gewichtete Varianz (für Variationsreihen):

wobei n die Häufigkeit ist (Wiederholbarkeit des Faktors X)
Ein Beispiel für die Ermittlung von Varianz
Auf dieser Seite wird ein Standardbeispiel zum Ermitteln der Varianz beschrieben. Sie können sich auch andere Probleme zum Ermitteln der Varianz ansehen
Beispiel 1. Bestimmung von Gruppe, Gruppendurchschnitt, Intergruppen- und Gesamtvarianz
Beispiel 2. Ermitteln der Varianz und des Variationskoeffizienten in einer Gruppierungstabelle
Beispiel 3. Varianz in einer diskreten Reihe ermitteln
Beispiel 4. Die folgenden Daten liegen für eine Gruppe von 20 Fernstudenten vor. Es ist notwendig, eine Intervallreihe der Verteilung des Merkmals zu erstellen, den Durchschnittswert des Merkmals zu berechnen und seine Streuung zu untersuchen

Lassen Sie uns eine Intervallgruppierung erstellen. Bestimmen wir den Bereich des Intervalls anhand der Formel:
![]()
wobei X max der Maximalwert des Gruppierungsmerkmals ist; X min – Mindestwert des Gruppierungsmerkmals; n – Anzahl der Intervalle:
Wir akzeptieren n=5. Der Schritt ist: h = (192 - 159)/ 5 = 6,6
Lassen Sie uns eine Intervallgruppierung erstellen

Für weitere Berechnungen erstellen wir eine Hilfstabelle:

X"i – die Mitte des Intervalls. (zum Beispiel die Mitte des Intervalls 159 – 165,6 = 162,3)
Wir ermitteln die durchschnittliche Körpergröße der Schüler anhand der gewichteten arithmetischen Durchschnittsformel:

Bestimmen wir die Varianz mit der Formel:
Die Formel lässt sich wie folgt umwandeln:

Aus dieser Formel folgt das Varianz ist gleich die Differenz zwischen dem Durchschnitt der Quadrate der Optionen und dem Quadrat und dem Durchschnitt.
Streuung in Variationsreihen mit gleichen Intervallen unter Verwendung der Momentenmethode kann auf folgende Weise unter Verwendung der zweiten Eigenschaft der Dispersion (Dividieren aller Optionen durch den Wert des Intervalls) berechnet werden. Varianz bestimmen, berechnet nach der Momentenmethode, ist die Verwendung der folgenden Formel weniger aufwendig:

wobei i der Wert des Intervalls ist; A ist eine konventionelle Nullstelle, für die es zweckmäßig ist, die Mitte des Intervalls mit der höchsten Frequenz zu verwenden; m1 ist das Quadrat des Moments erster Ordnung; m2 - Moment zweiter Ordnung
Alternative Merkmalsvarianz (Ändert sich in einer statistischen Grundgesamtheit ein Merkmal so, dass es nur zwei sich gegenseitig ausschließende Optionen gibt, dann nennt man diese Variabilität Alternative) lässt sich nach folgender Formel berechnen:

Wenn wir q = 1- p in diese Dispersionsformel einsetzen, erhalten wir:

Arten der Varianz
Gesamtvarianz misst die Variation eines Merkmals in der gesamten Population unter dem Einfluss aller Faktoren, die diese Variation verursachen. Sie entspricht dem mittleren Quadrat der Abweichungen einzelner Werte eines Merkmals x vom Gesamtmittelwert von x und kann als einfache Varianz oder gewichtete Varianz definiert werden.
Varianz innerhalb der Gruppe charakterisiert zufällige Variation, d.h. Teil der Variation, der auf den Einfluss nicht berücksichtigter Faktoren zurückzuführen ist und nicht von dem Faktorattribut abhängt, das die Grundlage der Gruppe bildet. Eine solche Streuung entspricht dem mittleren Quadrat der Abweichungen einzelner Werte des Attributs innerhalb der Gruppe X vom arithmetischen Mittel der Gruppe und kann als einfache Streuung oder als gewichtete Streuung berechnet werden.
Auf diese Weise, Varianzmaße innerhalb der Gruppe Variation eines Merkmals innerhalb einer Gruppe und wird durch die Formel bestimmt:

wobei xi der Gruppendurchschnitt ist; ni ist die Anzahl der Einheiten in der Gruppe.
Beispielsweise zeigen gruppeninterne Varianzen, die bei der Untersuchung des Einflusses der Qualifikationen der Arbeitnehmer auf das Niveau der Arbeitsproduktivität in einer Werkstatt ermittelt werden müssen, Schwankungen im Output in jeder Gruppe, die durch alle möglichen Faktoren (technischer Zustand der Ausrüstung, Verfügbarkeit von ...) verursacht werden Werkzeuge und Materialien, Alter der Arbeiter, Arbeitsintensität usw.), mit Ausnahme von Unterschieden in der Qualifikationskategorie (innerhalb einer Gruppe haben alle Arbeiter die gleichen Qualifikationen).
Der Durchschnitt der Varianzen innerhalb der Gruppe spiegelt die zufällige Variation wider, d. h. den Teil der Variation, der unter dem Einfluss aller anderen Faktoren mit Ausnahme des Gruppierungsfaktors auftrat. Die Berechnung erfolgt nach folgender Formel:

Intergruppenvarianz charakterisiert die systematische Variation des resultierenden Merkmals, die auf den Einfluss des der Gruppe zugrunde liegenden Faktorattributs zurückzuführen ist. Er entspricht dem mittleren Quadrat der Abweichungen der Gruppenmittelwerte vom Gesamtmittelwert. Die Intergruppenvarianz wird nach folgender Formel berechnet:

Variationsbereich (oder Variationsbereich) - Dies ist die Differenz zwischen den Maximal- und Minimalwerten des Merkmals:
In unserem Beispiel beträgt die Schwankungsbreite der Schichtleistung der Arbeiter: in der ersten Brigade R = 105-95 = 10 Kinder, in der zweiten Brigade R = 125-75 = 50 Kinder. (5 mal mehr). Dies deutet darauf hin, dass die Leistung der 1. Brigade „stabiler“ ist, die zweite Brigade jedoch über mehr Reserven zur Leistungssteigerung verfügt, weil Wenn alle Arbeiter die maximale Leistung dieser Brigade erreichen, kann sie 3 * 125 = 375 Teile produzieren, in der 1. Brigade nur 105 * 3 = 315 Teile.
Wenn die Extremwerte eines Merkmals nicht typisch für die Grundgesamtheit sind, werden Quartil- oder Dezilbereiche verwendet. Der Quartilbereich RQ= Q3-Q1 deckt 50 % des Bevölkerungsvolumens ab, der erste Dezilbereich RD1 = D9-D1 deckt 80 % der Daten ab, der zweite Dezilbereich RD2= D8-D2 – 60 %.
Der Nachteil des Variationsbereichsindikators besteht darin, dass sein Wert nicht alle Schwankungen des Merkmals widerspiegelt.
Der einfachste allgemeine Indikator, der alle Schwankungen eines Merkmals widerspiegelt, ist durchschnittliche lineare Abweichung, das ist das arithmetische Mittel der absoluten Abweichungen einzelner Optionen von ihrem Durchschnittswert:
,
für gruppierte Daten ![]() ,
,
Dabei ist xi der Wert des Attributs in einer diskreten Reihe oder die Mitte des Intervalls in der Intervallverteilung.
In den obigen Formeln werden die Differenzen im Zähler modulo gebildet, andernfalls ist der Zähler gemäß der Eigenschaft des arithmetischen Mittels immer gleich Null. Daher wird die durchschnittliche lineare Abweichung in der statistischen Praxis selten verwendet, sondern nur in Fällen, in denen die Summierung von Indikatoren ohne Berücksichtigung des Vorzeichens wirtschaftlich sinnvoll ist. Mit seiner Hilfe werden beispielsweise die Zusammensetzung der Belegschaft, die Rentabilität der Produktion und Außenhandelsumsätze analysiert.
Varianz eines Merkmals ist das durchschnittliche Quadrat der Abweichungen von ihrem Durchschnittswert:
einfache Varianz ![]() ,
,
Varianzgewichtet  .
.
Die Formel zur Berechnung der Varianz kann vereinfacht werden:
Somit ist die Varianz gleich der Differenz zwischen dem Mittelwert der Quadrate der Option und dem Quadrat des Mittelwerts der Populationsoption:  .
.
Aufgrund der Summation der quadrierten Abweichungen ergibt die Varianz jedoch ein verzerrtes Bild der Abweichungen, sodass der Durchschnitt auf dieser Grundlage berechnet wird Standardabweichung, die zeigt, wie stark bestimmte Varianten eines Merkmals im Durchschnitt von ihrem Durchschnittswert abweichen. Berechnet durch Ziehen der Quadratwurzel der Varianz:
für nicht gruppierte Daten 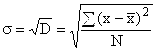 ,
,
für Variationsreihen 
Je kleiner der Wert der Varianz und der Standardabweichung ist, je homogener die Grundgesamtheit ist, desto zuverlässiger (typischer) ist der Durchschnittswert.
Durchschnittliche lineare Abweichung und Standardabweichung sind benannte Zahlen, d. h. sie werden in Maßeinheiten eines Merkmals ausgedrückt, sind inhaltlich identisch und haben eine ähnliche Bedeutung.
Es empfiehlt sich, absolute Abweichungen anhand von Tabellen zu berechnen.
Tabelle 3 – Berechnung der Variationsmerkmale (am Beispiel des Zeitraums der Daten zur Schichtleistung von Mannschaftsarbeitern)
Anzahl der Arbeiter |
Die Mitte des Intervalls |
Berechnete Werte |
|||||
Gesamt: |
|||||||
Durchschnittliche Schichtleistung der Arbeiter: ![]()
Durchschnittliche lineare Abweichung: ![]()
Produktionsabweichung: 
Die Standardabweichung der Leistung einzelner Arbeitnehmer von der durchschnittlichen Leistung:
.
1 Berechnung der Streuung nach der Momentenmethode
Die Berechnung von Varianzen erfordert umständliche Berechnungen (insbesondere, wenn der Durchschnitt als große Zahl mit mehreren Dezimalstellen ausgedrückt wird). Berechnungen können durch die Verwendung einer vereinfachten Formel und Dispersionseigenschaften vereinfacht werden.
Die Dispersion hat folgende Eigenschaften:
- Wenn alle Werte eines Merkmals um denselben Wert A verringert oder erhöht werden, verringert sich die Streuung nicht:
 ,
,
 , dann oder
, dann oder 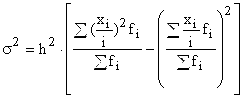
Indem wir die Eigenschaften der Streuung nutzen und zunächst alle Varianten der Grundgesamtheit um den Wert A reduzieren und dann durch den Wert des Intervalls h dividieren, erhalten wir eine Formel zur Berechnung der Streuung in Variationsreihen mit gleichen Intervallen Art und Weise der Momente: ,
,
wo wird die Streuung nach der Momentenmethode berechnet?
h – Wert des Intervalls der Variationsreihe;
– Option für neue (transformierte) Werte;
A ist ein konstanter Wert, der als Mitte des Intervalls mit der höchsten Häufigkeit verwendet wird; oder die Option mit der höchsten Häufigkeit;  – Quadrat des Moments erster Ordnung;
– Quadrat des Moments erster Ordnung;
– Moment zweiter Ordnung.
Berechnen wir die Streuung mithilfe der Momentenmethode basierend auf Daten über die Schichtleistung der Mitarbeiter des Teams.
Tabelle 4 – Berechnung der Varianz mit der Momentenmethode
Gruppen von Produktionsarbeitern, Stck. |
Anzahl der Arbeiter |
Die Mitte des Intervalls |
Berechnete Werte |
||
Berechnungsverfahren:


- Wir berechnen die Varianz:
2 Berechnung der Varianz eines alternativen Merkmals
Unter den von der Statistik untersuchten Merkmalen gibt es auch solche, die nur zwei sich gegenseitig ausschließende Bedeutungen haben. Dies sind alternative Zeichen. Sie erhalten jeweils zwei quantitative Werte: Option 1 und 0. Die Häufigkeit von Option 1, die mit p bezeichnet wird, ist der Anteil der Einheiten, die dieses Merkmal besitzen. Die Differenz 1-ð=q ist die Häufigkeit der Optionen 0. Somit gilt
xi |
|
Arithmetisches Mittel des Alternativzeichens ![]() , weil p+q=1.
, weil p+q=1.
Alternative Merkmalsvarianz
, Weil 1-ð=q
Somit ist die Varianz eines alternativen Merkmals gleich dem Produkt aus dem Anteil der Einheiten, die dieses Merkmal besitzen, und dem Anteil der Einheiten, die dieses Merkmal nicht besitzen.
Treten die Werte 1 und 0 gleich häufig auf, also p=q, erreicht die Varianz ihr Maximum pq=0,25.
Die Varianz eines Alternativmerkmals wird in Stichprobenerhebungen beispielsweise zur Produktqualität verwendet.
3 Varianz zwischen Gruppen. Varianzadditionsregel
Im Gegensatz zu anderen Variationsmerkmalen handelt es sich bei der Dispersion um eine additive Größe. Das heißt, im Aggregat, das nach Faktormerkmalen in Gruppen eingeteilt wird X , Varianz des resultierenden Merkmals j kann in die Varianz innerhalb jeder Gruppe (innerhalb von Gruppen) und die Varianz zwischen Gruppen (zwischen Gruppen) zerlegt werden. Dann wird es neben der Untersuchung der Variation eines Merkmals in der gesamten Population auch möglich, die Variation in jeder Gruppe sowie zwischen diesen Gruppen zu untersuchen.
Gesamtvarianz misst die Variation eines Merkmals bei in seiner Gesamtheit unter dem Einfluss aller Faktoren, die diese Variation (Abweichungen) verursacht haben. Sie entspricht der mittleren quadratischen Abweichung einzelner Werte des Attributs bei aus dem Gesamtdurchschnitt und kann als einfache oder gewichtete Varianz berechnet werden.
Intergruppenvarianz charakterisiert die Variation des resultierenden Merkmals bei verursacht durch den Einfluss des Faktorzeichens X, die die Grundlage der Gruppierung bildete. Es charakterisiert die Variation der Gruppendurchschnitte und entspricht dem mittleren Quadrat der Abweichungen der Gruppendurchschnitte vom Gesamtdurchschnitt:  ,
,
wo ist das arithmetische Mittel der i-ten Gruppe;
– Anzahl der Einheiten in der i-ten Gruppe (Häufigkeit der i-ten Gruppe);
– der Gesamtdurchschnitt der Bevölkerung.
Varianz innerhalb der Gruppe spiegelt die zufällige Variation wider, d. h. den Teil der Variation, der durch den Einfluss nicht berücksichtigter Faktoren verursacht wird und nicht von dem Faktorattribut abhängt, das die Grundlage der Gruppierung bildet. Es charakterisiert die Variation einzelner Werte relativ zu Gruppendurchschnitten und ist gleich der mittleren quadratischen Abweichung einzelner Werte des Attributs bei innerhalb einer Gruppe aus dem arithmetischen Mittel dieser Gruppe (Gruppenmittel) und wird als einfache oder gewichtete Varianz für jede Gruppe berechnet: ![]() oder
oder ![]() ,
,
Wo ist die Anzahl der Einheiten in der Gruppe?
Basierend auf den gruppeninternen Varianzen für jede Gruppe kann man bestimmen Gesamtmittelwert der gruppeninternen Varianzen:
.
Den Zusammenhang zwischen den drei Streuungen nennt man Regeln zum Addieren von Varianzen, wonach die Gesamtvarianz gleich der Summe der Varianz zwischen den Gruppen und dem Durchschnitt der Varianzen innerhalb der Gruppe ist:
Beispiel. Bei der Untersuchung des Einflusses der Tarifkategorie (Qualifikation) von Arbeitnehmern auf die Höhe ihrer Arbeitsproduktivität wurden folgende Daten ermittelt.
Tabelle 5 – Verteilung der Arbeitnehmer nach durchschnittlicher Stundenleistung.
№ p/p |
Arbeiter der 4. Kategorie |
Arbeiter der 5. Kategorie |
|||||
Ausgabe |
Ausgabe |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
In diesem Beispiel werden Arbeitnehmer nach Faktormerkmalen in zwei Gruppen eingeteilt X– Qualifikationen, die durch ihren Rang gekennzeichnet sind. Das resultierende Merkmal – die Produktion – variiert sowohl unter seinem Einfluss (Intergruppenvariation) als auch aufgrund anderer Zufallsfaktoren (Intragruppenvariation). Das Ziel besteht darin, diese Variationen anhand von drei Varianzen zu messen: insgesamt, zwischen Gruppen und innerhalb von Gruppen. Das empirische Bestimmtheitsmaß gibt den Variationsanteil des resultierenden Merkmals an bei unter dem Einfluss eines Faktorzeichens X. Rest der Gesamtvariante bei verursacht durch Veränderungen anderer Faktoren.
Im Beispiel beträgt das empirische Bestimmtheitsmaß: ![]() oder 66,7 %,
oder 66,7 %,
Dies bedeutet, dass 66,7 % der Unterschiede in der Arbeitsproduktivität auf Qualifikationsunterschiede zurückzuführen sind und 33,3 % auf den Einfluss anderer Faktoren zurückzuführen sind.
Empirische Korrelationsbeziehung zeigt den engen Zusammenhang zwischen Gruppierung und Leistungsmerkmalen. Berechnet als Quadratwurzel des empirischen Bestimmtheitsmaßes:
Das empirische Korrelationsverhältnis kann Werte von 0 bis 1 annehmen.
Wenn keine Verbindung besteht, dann =0. In diesem Fall =0, d. h. die Gruppenmittelwerte sind einander gleich und es gibt keine Variation zwischen den Gruppen. Dies bedeutet, dass das Gruppierungsmerkmal - Faktor keinen Einfluss auf die Bildung allgemeiner Variation hat.
Wenn die Verbindung funktionsfähig ist, dann =1. In diesem Fall ist die Varianz der Gruppenmittelwerte gleich der Gesamtvarianz (), d. h. es gibt keine Variation innerhalb der Gruppe. Dies bedeutet, dass das Gruppierungsmerkmal vollständig die Variation des untersuchten resultierenden Merkmals bestimmt.
Je näher der Wert des Korrelationsverhältnisses an Eins liegt, desto näher, näher an der funktionalen Abhängigkeit, ist der Zusammenhang zwischen den Merkmalen.
Um die Nähe des Zusammenhangs zwischen Merkmalen qualitativ zu beurteilen, werden Chaddock-Relationen verwendet.
Im Beispiel ![]() , was auf einen engen Zusammenhang zwischen der Produktivität der Arbeitnehmer und ihren Qualifikationen hinweist.
, was auf einen engen Zusammenhang zwischen der Produktivität der Arbeitnehmer und ihren Qualifikationen hinweist.
Wenn die Grundgesamtheit entsprechend dem untersuchten Merkmal in Gruppen eingeteilt wird, können für diese Grundgesamtheit die folgenden Varianzarten berechnet werden: Gesamt, Gruppe (innerhalb der Gruppe), Durchschnitt der Gruppe (Durchschnitt innerhalb der Gruppe), Intergruppe.
Zunächst wird der Bestimmtheitskoeffizient berechnet, der zeigt, welcher Teil der Gesamtvariation des untersuchten Merkmals eine Intergruppenvariation ist, d. h. aufgrund des Gruppierungsmerkmals:
Die empirische Korrelationsbeziehung charakterisiert die Nähe des Zusammenhangs zwischen Gruppierung (Fakultät) und Leistungsmerkmalen.
Das empirische Korrelationsverhältnis kann Werte von 0 bis 1 annehmen.
Um die Nähe des Zusammenhangs anhand des empirischen Korrelationsverhältnisses zu beurteilen, können Sie die Chaddock-Relationen verwenden:
Beispiel 4. Zur Arbeitsleistung von Planungs- und Vermessungsorganisationen unterschiedlicher Eigentumsformen liegen folgende Daten vor:
Definieren:
1) Gesamtvarianz;
2) Gruppenvarianzen;
3) der Durchschnitt der Gruppenvarianzen;
4) Intergruppenvarianz;
5) Gesamtvarianz basierend auf der Regel zum Addieren von Varianzen;
6) Bestimmtheitsmaß und empirisches Korrelationsverhältnis.
Schlussfolgerungen.
Lösung:
1. Bestimmen wir das durchschnittliche Arbeitsvolumen von Unternehmen mit zwei Eigentumsformen:
Berechnen wir die Gesamtvarianz:
![]()
2. Gruppendurchschnitte ermitteln:
![]() Millionen Rubel;
Millionen Rubel;
![]() Millionen Rubel
Millionen Rubel
Gruppenabweichungen:
![]() ;
;
3. Berechnen Sie den Durchschnitt der Gruppenvarianzen:
4. Bestimmen wir die Intergruppenvarianz:
5. Berechnen Sie die Gesamtvarianz basierend auf der Regel zum Addieren von Varianzen:
6. Bestimmen wir das Bestimmtheitsmaß:
![]() .
.
So hängt der Umfang der von Planungs- und Vermessungsorganisationen geleisteten Arbeit zu 22 % von der Eigentumsform der Unternehmen ab.
Das empirische Korrelationsverhältnis wird anhand der Formel berechnet
![]() .
.
Der Wert des berechneten Indikators zeigt, dass die Abhängigkeit des Arbeitsvolumens von der Eigentumsform des Unternehmens gering ist.
Beispiel 5. Als Ergebnis einer Erhebung zur technologischen Disziplin der Produktionsbereiche wurden folgende Daten erhoben:
Bestimmen Sie das Bestimmtheitsmaß
Rechnen wir einMSAUSGEZEICHNETStichprobenvarianz und Standardabweichung. Wir berechnen auch die Varianz einer Zufallsvariablen, wenn ihre Verteilung bekannt ist.
Lassen Sie uns zunächst überlegen Streuung, Dann Standardabweichung.
Stichprobenvarianz
Stichprobenvarianz (Stichprobenvarianz,ProbeVarianz) charakterisiert die Streuung der Werte im Array relativ zu .
Alle 3 Formeln sind mathematisch äquivalent.
Aus der ersten Formel geht das klar hervor Stichprobenvarianz ist die Summe der quadrierten Abweichungen jedes Werts im Array vom Durchschnitt, geteilt durch Stichprobengröße minus 1.
Abweichungen Proben die Funktion DISP() wird verwendet, Englisch. der Name VAR, d.h. VARIANTE. Ab Version MS EXCEL 2010 wird empfohlen, dessen analoges DISP.V(), Englisch, zu verwenden. der Name VARS, d.h. Beispielvarianz. Darüber hinaus gibt es ab der Version von MS EXCEL 2010 eine Funktion DISP.Г(), Englisch. der Name VARP, d.h. Bevölkerungsvarianz, die berechnet wird Streuung Für Bevölkerung. Der ganze Unterschied liegt im Nenner: Anstelle von n-1 wie DISP.V() hat DISP.G() nur n im Nenner. Vor MS EXCEL 2010 wurde die Funktion VAR() zur Berechnung der Varianz der Grundgesamtheit verwendet.
Stichprobenvarianz
=QUADROTCL(Probe)/(COUNT(Probe)-1)
=(SUMME(Probe)-ANZAHL(Probe)*DURCHSCHNITT(Probe)^2)/ (ANZAHL(Probe)-1)– übliche Formel
=SUM((Probe -AVERAGE(Probe))^2)/ (COUNT(Probe)-1) –
Stichprobenvarianz ist nur dann gleich 0, wenn alle Werte einander gleich und dementsprechend gleich sind Durchschnittswert. Normalerweise gilt: Je größer der Wert Abweichungen, desto größer ist die Streuung der Werte im Array.
Stichprobenvarianz ist eine Punktschätzung Abweichungen Verteilung der Zufallsvariablen, aus der sie erstellt wurde Probe. Über den Bau Vertrauensintervalle bei der Beurteilung Abweichungen kann im Artikel nachgelesen werden.
Varianz einer Zufallsvariablen
Berechnen Streuung Zufallsvariable, Sie müssen es wissen.
Für Abweichungen Die Zufallsvariable X wird oft als Var(X) bezeichnet. Streuung gleich dem Quadrat der Abweichung vom Mittelwert E(X): Var(X)=E[(X-E(X)) 2 ]
Streuung berechnet nach der Formel:

Dabei ist x i der Wert, den eine Zufallsvariable annehmen kann, und μ der Durchschnittswert (), p(x) ist die Wahrscheinlichkeit, dass die Zufallsvariable den Wert x annehmen wird.
Wenn eine Zufallsvariable hat, dann Streuung berechnet nach der Formel:

Abmessungen Abweichungen entspricht dem Quadrat der Maßeinheit der ursprünglichen Werte. Wenn die Werte in der Stichprobe beispielsweise Teilgewichtsmessungen (in kg) darstellen, wäre die Varianzdimension kg 2 . Dies kann schwierig zu interpretieren sein. Um die Streuung der Werte zu charakterisieren, ist ein Wert erforderlich, der der Quadratwurzel entspricht Abweichungen – Standardabweichung.
Einige Eigenschaften Abweichungen:
Var(X+a)=Var(X), wobei X eine Zufallsvariable und a eine Konstante ist.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Diese Dispersionseigenschaft wird in verwendet Artikel über lineare Regression.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), wobei X und Y Zufallsvariablen sind, Cov(X;Y) die Kovarianz dieser Zufallsvariablen.
Wenn Zufallsvariablen unabhängig sind, dann sind sie Kovarianz ist gleich 0 und daher Var(X+Y)=Var(X)+Var(Y). Diese Dispersionseigenschaft wird bei der Ableitung genutzt.
Zeigen wir, dass für unabhängige Größen Var(X-Y)=Var(X+Y) ist. Tatsächlich ist Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Diese Dispersionseigenschaft wird zum Konstruieren verwendet.
Standardabweichung der Stichprobe
Standardabweichung der Stichprobe ist ein Maß dafür, wie stark die Werte in einer Stichprobe im Verhältnis zu ihrem Wert streuen.
A-Priorat, Standardabweichung gleich der Quadratwurzel von Abweichungen:

Standardabweichung berücksichtigt nicht die Größe der Werte in Probe, sondern nur der Grad der Streuung der Werte um sie herum Durchschnitt. Um dies zu veranschaulichen, geben wir ein Beispiel.
Berechnen wir die Standardabweichung für zwei Stichproben: (1; 5; 9) und (1001; 1005; 1009). In beiden Fällen ist s=4. Es ist offensichtlich, dass sich das Verhältnis der Standardabweichung zu den Array-Werten zwischen den Stichproben erheblich unterscheidet. Für solche Fälle wird es verwendet Der Variationskoeffizient(Variationskoeffizient, CV) – Verhältnis Standardabweichung zum Durchschnitt Arithmetik, ausgedrückt als Prozentsatz.
In MS EXCEL 2007 und früheren Versionen zur Berechnung Standardabweichung der Stichprobe Es wird die Funktion =STDEVAL() verwendet, Englisch. Name STDEV, d.h. Standardabweichung. Ab der Version von MS EXCEL 2010 wird empfohlen, dessen Analogon =STDEV.B() , Englisch, zu verwenden. Name STDEV.S, d.h. Beispiel einer Standardabweichung.
Darüber hinaus gibt es ab der Version von MS EXCEL 2010 eine Funktion STANDARDEV.G(), Englisch. Name STDEV.P, d.h. Bevölkerungsstandardabweichung, die berechnet wird Standardabweichung Für Bevölkerung. Der ganze Unterschied liegt im Nenner: Anstelle von n-1 wie in STANDARDEV.V() hat STANDARDEVAL.G() nur n im Nenner.
Standardabweichung kann auch direkt mit den untenstehenden Formeln berechnet werden (siehe Beispieldatei)
=ROOT(QUADROTCL(Probe)/(COUNT(Probe)-1))
=ROOT((SUM(Probe)-COUNT(Probe)*AVERAGE(Probe)^2)/(COUNT(Probe)-1))
Andere Streumaße
Die Funktion SQUADROTCL() rechnet mit eine Summe quadrierter Abweichungen von Werten von ihrem Durchschnitt. Diese Funktion liefert das gleiche Ergebnis wie die Formel =DISP.G( Probe)*ÜBERPRÜFEN( Probe) , Wo Probe– ein Verweis auf einen Bereich, der ein Array von Beispielwerten enthält (). Berechnungen in der Funktion QUADROCL() erfolgen nach der Formel:

Die SROTCL()-Funktion ist auch ein Maß für die Ausbreitung eines Datensatzes. Die Funktion SROTCL() berechnet den Durchschnitt der absoluten Werte der Abweichungen von Werten Durchschnitt. Diese Funktion gibt das gleiche Ergebnis wie die Formel zurück =SUMPRODUCT(ABS(Probe-AVERAGE(Probe)))/COUNT(Probe), Wo Probe– ein Link zu einem Bereich, der ein Array von Beispielwerten enthält.
Berechnungen in der Funktion SROTCL() erfolgen nach der Formel:

Streuungzufällige Variable- Maß für die Ausbreitung eines bestimmten zufällige Variable, das ist sie Abweichungen aus mathematischer Erwartung. In der Statistik wird häufig die Notation (Sigma-Quadrat) zur Angabe der Streuung verwendet. Die Quadratwurzel der Varianz gleich heißt Standardabweichung oder Standardaufstrich. Die Standardabweichung wird in denselben Einheiten wie die Zufallsvariable selbst gemessen, und die Varianz wird in den Quadraten dieser Einheit gemessen.
Obwohl es sehr praktisch ist, nur einen Wert (z. B. den Mittelwert oder Modus und Median) zur Schätzung der gesamten Stichprobe zu verwenden, kann dieser Ansatz leicht zu falschen Schlussfolgerungen führen. Der Grund für diese Situation liegt nicht im Wert selbst, sondern darin, dass ein Wert in keiner Weise die Streuung der Datenwerte widerspiegelt.
Im Beispiel zum Beispiel:
der Durchschnittswert liegt bei 5.
Allerdings gibt es in der Stichprobe selbst kein einziges Element mit einem Wert von 5. Möglicherweise müssen Sie den Grad der Nähe jedes Elements in der Stichprobe zu seinem Mittelwert kennen. Mit anderen Worten: Sie müssen die Varianz der Werte kennen. Wenn Sie den Grad der Datenänderung kennen, können Sie sie besser interpretieren mittlere Bedeutung, Median Und Mode. Der Grad der Änderung der Stichprobenwerte wird durch die Berechnung ihrer Varianz und Standardabweichung bestimmt.
Die Varianz und die Quadratwurzel der Varianz, die sogenannte Standardabweichung, charakterisieren die durchschnittliche Abweichung vom Stichprobenmittelwert. Unter diesen beiden Größen ist die wichtigste Standardabweichung. Man kann sich diesen Wert als den durchschnittlichen Abstand vorstellen, den Elemente vom mittleren Element der Stichprobe haben.
Varianz ist schwer sinnvoll zu interpretieren. Allerdings ist die Quadratwurzel dieses Wertes die Standardabweichung und kann leicht interpretiert werden.
Die Standardabweichung wird berechnet, indem zunächst die Varianz bestimmt und dann die Quadratwurzel aus der Varianz gezogen wird.
Für das in der Abbildung gezeigte Datenarray werden beispielsweise die folgenden Werte erhalten:

Bild 1
Hier beträgt der Mittelwert der quadrierten Differenzen 717,43. Um die Standardabweichung zu erhalten, müssen Sie nur noch die Quadratwurzel dieser Zahl ziehen.
Das Ergebnis wird ungefähr 26,78 sein.
Denken Sie daran, dass die Standardabweichung als der durchschnittliche Abstand der Elemente vom Stichprobenmittelwert interpretiert wird.
Die Standardabweichung misst, wie gut der Mittelwert die gesamte Stichprobe beschreibt.
Nehmen wir an, Sie sind Leiter einer Produktionsabteilung für PC-Baugruppen. Im Quartalsbericht heißt es, dass die Produktion im letzten Quartal 2.500 PCs betrug. Ist das gut oder schlecht? Sie haben darum gebeten (oder es gibt diese Spalte bereits im Bericht), die Standardabweichung für diese Daten im Bericht anzuzeigen. Die Standardabweichung beträgt beispielsweise 2000. Für Sie als Abteilungsleiter wird deutlich, dass die Produktionslinie einer besseren Steuerung bedarf (zu große Abweichungen bei der Anzahl der montierten PCs).
Denken Sie daran, dass bei einer großen Standardabweichung die Daten weit um den Mittelwert herum verstreut sind und dass sie bei einer kleinen Standardabweichung nahe am Mittelwert liegen.
Die vier Statistikfunktionen VAR(), VAR(), STDEV() und STDEV() dienen zur Berechnung der Varianz und Standardabweichung von Zahlen in einem Zellbereich. Bevor Sie die Varianz und Standardabweichung eines Datensatzes berechnen können, müssen Sie bestimmen, ob die Daten eine Grundgesamtheit oder eine Stichprobe einer Grundgesamtheit darstellen. Bei einer Stichprobe aus einer Grundgesamtheit sollten Sie die Funktionen VAR() und STDEV() verwenden, bei einer Grundgesamtheit die Funktionen VAR() und STDEV():
| Bevölkerung | Funktion |
 | DISPR() |
 | STANDOTLONP() |
| Probe | |
 | DISP() |
 | STDEV() |
Die Streuung (sowie die Standardabweichung) gibt, wie bereits erwähnt, das Ausmaß an, in dem die im Datensatz enthaltenen Werte um das arithmetische Mittel gestreut sind.
Ein kleiner Varianz- oder Standardabweichungswert zeigt an, dass sich alle Daten um das arithmetische Mittel konzentrieren, und ein großer Wert dieser Werte zeigt an, dass die Daten über einen weiten Wertebereich verstreut sind.
Die Varianz ist ziemlich schwer sinnvoll zu interpretieren (was bedeutet ein kleiner Wert, ein großer Wert?). Leistung Aufgaben 3 ermöglicht es Ihnen, die Bedeutung der Varianz für einen Datensatz in einem Diagramm visuell darzustellen.
Aufgaben
· Übung 1.
· 2.1. Geben Sie die Konzepte an: Streuung und Standardabweichung; ihre symbolische Bezeichnung für die statistische Datenverarbeitung.
· 2.2. Füllen Sie das Arbeitsblatt gemäß Abbildung 1 aus und führen Sie die erforderlichen Berechnungen durch.
· 2.3. Geben Sie die Grundformeln an, die bei Berechnungen verwendet werden
· 2.4. Erklären Sie alle Bezeichnungen ( , , )
· 2.5. Erklären Sie die praktische Bedeutung der Konzepte Streuung und Standardabweichung.
Aufgabe 2.
1.1. Geben Sie die Konzepte an: Allgemeinbevölkerung und Stichprobe; mathematische Erwartung und ihr arithmetisches Mittel symbolische Bezeichnung für die statistische Datenverarbeitung.
1.2. Bereiten Sie gemäß Abbildung 2 ein Arbeitsblatt vor und führen Sie Berechnungen durch.
1.3. Geben Sie die Grundformeln an, die in den Berechnungen verwendet werden (für die allgemeine Bevölkerung und die Stichprobe).

Figur 2
1.4. Erklären Sie, warum es möglich ist, in Stichproben arithmetische Mittelwerte wie 46,43 und 48,78 zu erhalten (siehe Dateianhang). Schlussfolgerungen.
Aufgabe 3.
Es gibt zwei Stichproben mit unterschiedlichen Datensätzen, deren Durchschnitt jedoch gleich sein wird:

Figur 3
3.1. Füllen Sie das Arbeitsblatt gemäß Abbildung 3 aus und führen Sie die erforderlichen Berechnungen durch.
3.2. Geben Sie die grundlegenden Berechnungsformeln an.
3.3. Erstellen Sie Diagramme gemäß den Abbildungen 4, 5.
3.4. Erklären Sie die erhaltenen Abhängigkeiten.
3.5. Führen Sie ähnliche Berechnungen für die Daten von zwei Proben durch.
Originalmuster 11119999
Wählen Sie die Werte der zweiten Stichprobe so aus, dass das arithmetische Mittel für die zweite Stichprobe gleich ist, zum Beispiel:

Wählen Sie die Werte für die zweite Probe selbst aus. Ordnen Sie Berechnungen und Diagramme ähnlich wie in den Abbildungen 3, 4 und 5 an. Zeigen Sie die Grundformeln an, die in den Berechnungen verwendet wurden.
Ziehen Sie entsprechende Schlussfolgerungen.
Erledigen Sie alle Aufgaben in Form eines Berichts mit allen notwendigen Zeichnungen, Grafiken, Formeln und kurzen Erläuterungen.
Hinweis: Der Aufbau von Diagrammen muss durch Zeichnungen und kurze Erläuterungen erläutert werden.










