Wahrscheinlichkeitstheorie, Verteilungsgesetz. Bernoulli und Uniform
Die Binomialverteilung ist eine der wichtigsten Wahrscheinlichkeitsverteilungen einer diskret variierenden Zufallsvariablen. Die Binomialverteilung ist die Wahrscheinlichkeitsverteilung der Zahl M Eintreten eines Ereignisses A V N voneinander unabhängige Beobachtungen. Oft ein Ereignis A wird als „Erfolg“ einer Beobachtung bezeichnet, das gegenteilige Ereignis als „Misserfolg“, aber diese Bezeichnung ist sehr bedingt.
Binomialverteilungsbedingungen:
- insgesamt durchgeführt N Prüfungen, in denen die Veranstaltung A kann auftreten oder auch nicht;
- Ereignis A in jedem Versuch kann mit der gleichen Wahrscheinlichkeit auftreten P;
- Tests sind voneinander unabhängig.
Die Wahrscheinlichkeit, dass in N Testveranstaltung A es wird genau kommen M Zeiten, kann mit der Bernoulli-Formel berechnet werden:
![]()
![]() ,
,
Wo P- Wahrscheinlichkeit des Eintretens eines Ereignisses A;
Q = 1 - P- die Wahrscheinlichkeit, dass das gegenteilige Ereignis eintritt.
Lass es uns herausfinden Warum hängt die Binomialverteilung in der oben beschriebenen Weise mit der Bernoulli-Formel zusammen? . Ereignis - Anzahl der Erfolge bei N Tests sind in eine Reihe von Optionen unterteilt, bei denen jeweils ein Erfolg erzielt wird M Tests und Misserfolge - in N - M Tests. Betrachten wir eine dieser Optionen: B1 . Mit der Regel zum Addieren von Wahrscheinlichkeiten multiplizieren wir die Wahrscheinlichkeiten entgegengesetzter Ereignisse:
![]() ,
,
und wenn wir bezeichnen Q = 1 - P, Das
![]() .
.
Jede andere Option, bei der M Erfolg und N - M Misserfolge. Die Anzahl solcher Optionen entspricht der Anzahl der Möglichkeiten, die man haben kann N Testen Sie es M Erfolg.
Summe aller Wahrscheinlichkeiten M Ereignisvorkommensnummern A(Zahlen von 0 bis N) ist gleich eins:

wobei jeder Begriff einen Begriff im Newtonschen Binomial darstellt. Daher wird die betrachtete Verteilung Binomialverteilung genannt.
In der Praxis ist es oft notwendig, Wahrscheinlichkeiten „nicht mehr als“ zu berechnen M Erfolg in N Tests“ oder „zumindest M Erfolg in N Tests". Hierzu werden die folgenden Formeln verwendet.
Die Integralfunktion also Wahrscheinlichkeit F(M) was drin ist N Beobachtungsereignis A es wird nichts mehr kommen M einmal, kann nach folgender Formel berechnet werden:
Wiederum Wahrscheinlichkeit F(≥M) was drin ist N Beobachtungsereignis A wird nicht weniger kommen M einmal, wird nach der Formel berechnet:
Manchmal ist es bequemer, die Wahrscheinlichkeit dafür zu berechnen N Beobachtungsereignis A es wird nichts mehr kommen M mal durch die Wahrscheinlichkeit des entgegengesetzten Ereignisses:
![]() .
.
Welche Formel verwendet werden soll, hängt davon ab, bei welcher Formel die Summe weniger Terme enthält.
Die Eigenschaften der Binomialverteilung werden mit den folgenden Formeln berechnet .
Erwarteter Wert: .
Streuung: .
Standardabweichung: .
Binomialverteilung und Berechnungen in MS Excel
Binomiale Wahrscheinlichkeit P N ( M) und die Werte der Integralfunktion F(M) kann mit der MS Excel-Funktion BINOM.VERT berechnet werden. Das Fenster für die entsprechende Berechnung wird unten angezeigt (Linksklick zum Vergrößern).
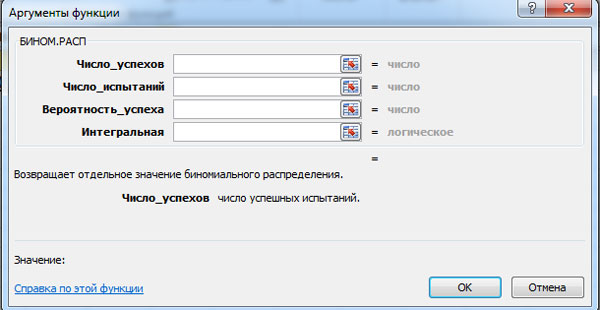
MS Excel erfordert die Eingabe folgender Daten:
- Anzahl der Erfolge;
- Anzahl der Tests;
- Erfolgswahrscheinlichkeit;
- Integral – logischer Wert: 0 – wenn Sie die Wahrscheinlichkeit berechnen müssen P N ( M) und 1 - wenn die Wahrscheinlichkeit F(M).
Beispiel 1. Der Unternehmensleiter fasste Informationen zur Anzahl der in den letzten 100 Tagen verkauften Kameras zusammen. Die Tabelle fasst die Informationen zusammen und berechnet die Wahrscheinlichkeiten, dass eine bestimmte Anzahl Kameras pro Tag verkauft wird.
Der Tag endet mit einem Gewinn, wenn 13 oder mehr Kameras verkauft werden. Wahrscheinlichkeit, dass der Tag gewinnbringend verläuft:
![]()
Wahrscheinlichkeit, dass ein Tag ohne Gewinn gearbeitet wird:

Die Wahrscheinlichkeit, dass an einem Tag mit Gewinn gearbeitet wird, sei konstant und gleich 0,61, und die Anzahl der pro Tag verkauften Kameras sei nicht vom Tag abhängig. Dann können wir die Binomialverteilung verwenden, bei der das Ereignis auftritt A- Der Tag wird mit Gewinn gearbeitet, - ohne Gewinn.
Wahrscheinlichkeit, dass alle 6 Tage mit Gewinn erarbeitet werden:
![]() .
.
Das gleiche Ergebnis erhalten wir mit der MS Excel-Funktion BINOM.VERT (der Wert des Integralwerts ist 0):
P 6 (6 ) = BINOM.VERT(6; 6; 0,61; 0) = 0,052.
Die Wahrscheinlichkeit, dass von 6 Tagen 4 oder mehr Tage mit Gewinn gearbeitet werden:
Wo ![]() ,
,
![]() ,
,
Mit der MS-Excel-Funktion BINOM.VERT berechnen wir die Wahrscheinlichkeit, dass von 6 Tagen nicht mehr als 3 Tage mit Gewinn abgeschlossen werden (der Wert des Integralwerts beträgt 1):
P 6 (≤3 ) = BINOM.VERT(3; 6; 0,61; 1) = 0,435.
Wahrscheinlichkeit, dass alle 6 Tage mit Verlusten durchgearbeitet werden:
![]() ,
,
Den gleichen Indikator können wir mit der MS Excel-Funktion BINOM.VERT berechnen:
P 6 (0 ) = BINOM.VERT(0; 6; 0,61; 0) = 0,0035.
Lösen Sie das Problem selbst und sehen Sie dann die Lösung
Beispiel 2. In der Urne befinden sich 2 weiße Kugeln und 3 schwarze Kugeln. Eine Kugel wird aus der Urne genommen, die Farbe eingestellt und zurückgelegt. Der Versuch wird 5 Mal wiederholt. Die Häufigkeit des Vorkommens weißer Kugeln ist eine diskrete Zufallsvariable X, verteilt nach dem Binomialgesetz. Erstellen Sie ein Verteilungsgesetz einer Zufallsvariablen. Definieren Sie Modus, mathematische Erwartung und Streuung.
Lassen Sie uns weiterhin gemeinsam Probleme lösen
Beispiel 3. Vom Kurierdienst aus gingen wir zu den Standorten N= 5 Kuriere. Jeder Kurier ist wahrscheinlich P= 0,3, unabhängig von anderen, ist zu spät für das Objekt. Diskrete Zufallsvariable X- Anzahl verspäteter Kuriere. Konstruieren Sie eine Verteilungsreihe für diese Zufallsvariable. Finden Sie den mathematischen Erwartungswert, die Varianz und die Standardabweichung. Ermitteln Sie die Wahrscheinlichkeit, dass mindestens zwei Kuriere zu spät für die Objekte kommen.
Trotz ihrer exotischen Namen beziehen sich gängige Verteilungen auf intuitive und interessante Weise aufeinander, sodass man sie sich leicht merken und mit Zuversicht darüber nachdenken kann. Einige ergeben sich natürlicherweise beispielsweise aus der Bernoulli-Verteilung. Zeit, eine Karte dieser Verbindungen zu zeigen.
Jede Verteilung wird durch ein Beispiel ihrer Verteilungsdichtefunktion (DFF) veranschaulicht. In diesem Artikel geht es nur um die Verteilungen, deren Ergebnisse einzelne Zahlen sind. Daher ist die horizontale Achse jedes Diagramms eine Menge möglicher Ergebniszahlen. Vertikal – die Wahrscheinlichkeit jedes Ergebnisses. Einige Verteilungen sind diskret – ihre Ergebnisse müssen ganze Zahlen sein, beispielsweise 0 oder 5. Diese werden durch dünne Linien angezeigt, eine für jedes Ergebnis, deren Höhe der Wahrscheinlichkeit eines bestimmten Ergebnisses entspricht. Einige sind kontinuierlich, ihre Ergebnisse können jeden numerischen Wert annehmen, beispielsweise -1,32 oder 0,005. Diese werden als dichte Kurven mit Flächen unter den Kurvenabschnitten dargestellt, die Wahrscheinlichkeiten angeben. Die Summe der Höhen von Linien und Flächen unter Kurven beträgt immer 1.
Drucken Sie es aus, schneiden Sie es entlang der gestrichelten Linie aus und tragen Sie es in Ihrer Brieftasche bei sich. Dies ist Ihr Leitfaden zum Land der Distributionen und ihrer Verwandten.
Bernoulli und Uniform
Sie sind bereits oben auf die Bernoulli-Verteilung gestoßen, mit zwei Ergebnissen – Kopf oder Zahl. Stellen Sie es sich jetzt als eine Verteilung über 0 und 1 vor, 0 bedeutet Kopf, 1 bedeutet Zahl. Wie bereits klar ist, sind beide Ergebnisse gleich wahrscheinlich, was sich auch im Diagramm widerspiegelt. Das Bernoulli-PDF enthält zwei Linien gleicher Höhe, die zwei gleich wahrscheinliche Ergebnisse darstellen: 0 bzw. 1.Die Bernoulli-Verteilung kann auch ungleich wahrscheinliche Ergebnisse darstellen, beispielsweise das Werfen einer falschen Münze. Dann beträgt die Wahrscheinlichkeit von „Kopf“ nicht 0,5, sondern ein anderer Wert p, und die Wahrscheinlichkeit von „Zahl“ beträgt 1-p. Wie viele andere Verteilungen handelt es sich hierbei tatsächlich um eine ganze Familie von Verteilungen, die durch bestimmte Parameter definiert werden, wie oben p. Wenn Sie an „Bernoulli“ denken, denken Sie an „das Werfen einer (möglicherweise falschen) Münze“.
Von hier aus ist es ein sehr kleiner Schritt, die Verteilung über mehreren gleich wahrscheinlichen Ergebnissen darzustellen: eine gleichmäßige Verteilung, die durch eine flache PDF gekennzeichnet ist. Stellen Sie sich einen normalen Würfel vor. Die Ergebnisse 1-6 sind gleich wahrscheinlich. Sie kann für eine beliebige Anzahl von Ergebnissen n und sogar als kontinuierliche Verteilung angegeben werden.
Stellen Sie sich eine gleichmäßige Verteilung als einen „geraden Würfel“ vor.
Binomial und hypergeometrisch
Die Binomialverteilung kann man sich als die Summe der Ergebnisse der Dinge vorstellen, die der Bernoulli-Verteilung folgen.Wirf eine faire Münze zweimal – wie oft wird es „Kopf“ sein? Dies ist eine Zahl, die der Binomialverteilung folgt. Seine Parameter sind n, die Anzahl der Versuche, und p – die Wahrscheinlichkeit des „Erfolgs“ (in unserem Fall Kopf oder 1). Jeder Wurf ist ein Bernoulli-verteiltes Ergebnis oder ein Test. Verwenden Sie die Binomialverteilung, wenn Sie die Anzahl der Erfolge zählen, beispielsweise beim Werfen einer Münze, bei der jeder Wurf unabhängig von den anderen ist und die gleiche Erfolgswahrscheinlichkeit hat.
Oder stellen Sie sich eine Urne mit der gleichen Anzahl weißer und schwarzer Kugeln vor. Schließen Sie die Augen, nehmen Sie den Ball heraus, notieren Sie seine Farbe und legen Sie ihn zurück. Wiederholen. Wie oft wird die schwarze Kugel gezogen? Auch diese Zahl folgt der Binomialverteilung.
Wir haben diese seltsame Situation dargestellt, um das Verständnis der Bedeutung der hypergeometrischen Verteilung zu erleichtern. Dies ist die Verteilung derselben Zahl, aber in der Situation, wenn wir Nicht gab die Bälle zurück. Sie ist sicherlich ein Verwandter der Binomialverteilung, aber nicht dieselbe, da sich die Erfolgswahrscheinlichkeit mit jeder gezogenen Kugel ändert. Wenn die Anzahl der Bälle im Vergleich zur Anzahl der Ziehungen groß genug ist, dann sind diese Verteilungen nahezu identisch, da sich die Erfolgsaussichten mit jeder Ziehung extrem geringfügig ändern.
Wenn jemand davon spricht, Kugeln aus Urnen zu ziehen, ohne sie zurückzugeben, ist es fast immer sicher, „Ja, hypergeometrische Verteilung“ zu sagen, denn ich habe noch nie in meinem Leben jemanden getroffen, der tatsächlich Urnen mit Kugeln gefüllt, sie dann herausgezogen und zurückgebracht hat , oder umgekehrt. Ich kenne niemanden mit Mülleimern. Noch häufiger sollte diese Verteilung auftreten, wenn eine signifikante Teilmenge einer Bevölkerung als Stichprobe ausgewählt wird.
Notiz Übersetzung
Es mag hier nicht ganz klar sein, aber da es sich bei dem Tutorial um einen Expresskurs für Anfänger handelt, sollte es klargestellt werden. Die Bevölkerung ist etwas, das wir statistisch auswerten wollen. Zur Schätzung wählen wir einen bestimmten Teil (Teilmenge) aus und nehmen darauf die erforderliche Schätzung vor (dann wird diese Teilmenge als Stichprobe bezeichnet), wobei wir davon ausgehen, dass die Schätzung für die gesamte Grundgesamtheit ähnlich sein wird. Damit dies jedoch zutrifft, sind häufig zusätzliche Einschränkungen bei der Definition einer Teilmenge der Stichprobe erforderlich (oder umgekehrt müssen wir bei einer bekannten Stichprobe beurteilen, ob sie die Grundgesamtheit hinreichend genau beschreibt).
Ein praktisches Beispiel: Wir müssen Vertreter eines Unternehmens mit 100 Mitarbeitern auswählen, die zur E3 reisen. Es ist bekannt, dass letztes Jahr bereits 10 Personen dorthin gereist sind (aber niemand gibt es zu). Wie viel muss man mindestens mitnehmen, damit mit hoher Wahrscheinlichkeit mindestens ein erfahrener Kamerad in der Gruppe ist? In diesem Fall beträgt die Grundgesamtheit 100, die Stichprobe 10, die Stichprobenanforderungen sind mindestens eine Person, die bereits E3 gefahren ist.
Wikipedia hat ein weniger lustiges, aber praktischeres Beispiel für fehlerhafte Teile in einer Charge.
Poisson
Wie hoch ist die Zahl der Kunden, die jede Minute die Hotline des technischen Supports anrufen? Dies ist ein Ergebnis, dessen Verteilung binomial zu sein scheint, wenn wir jede Sekunde als Bernoulli-Test zählen, in der der Kunde entweder nicht anruft (0) oder anruft (1). Aber Energieversorgungsunternehmen wissen ganz genau: Wenn der Strom ausfällt, können zwei Personen in einer Sekunde anrufen. oder sogar mehr als hundert von Leuten. Es hilft auch nicht, es sich als 60.000-Millisekunden-Tests vorzustellen – es gibt mehr Tests, die Wahrscheinlichkeit eines Anrufs pro Millisekunde ist geringer, selbst wenn man nicht zwei oder mehr gleichzeitig zählt, aber technisch gesehen ist das immer noch der Fall kein Bernoulli-Test. Allerdings funktioniert das logische Denken mit dem Übergang zur Unendlichkeit. Sei n gegen Unendlich und p gegen 0, so dass np konstant ist. Es ist, als würde man die Zeit in immer kleinere Zeitabschnitte aufteilen, wobei die Wahrscheinlichkeit eines Anrufs immer geringer wird. Im Grenzfall erhalten wir die Poisson-Verteilung.Genau wie die Binomialverteilung ist die Poisson-Verteilung eine Zählverteilung: die Häufigkeit, mit der etwas passiert. Sie wird nicht durch die Wahrscheinlichkeit p und die Anzahl der Versuche n parametrisiert, sondern durch die mittlere Intensität λ, die in Analogie zum Binomial einfach ein konstanter Wert np ist. Poisson-Verteilung – worum es geht notwendig Denken Sie daran, wenn wir über das Zählen von Ereignissen über einen bestimmten Zeitraum mit einer konstanten vorgegebenen Intensität sprechen.
Wenn etwas passiert, zum Beispiel Pakete, die an einem Router ankommen, oder Kunden, die in einem Geschäft erscheinen, oder etwas, das in der Schlange steht, denken Sie an „Poisson“.
Geometrisches und negatives Binomial
Aus einfachen Bernoulli-Tests ergibt sich eine andere Verteilung. Wie oft landet eine Münze auf dem Kopf, bevor sie auf dem Kopf landet? Die Anzahl der Schwänze folgt einer geometrischen Verteilung. Wie die Bernoulli-Verteilung wird sie durch die Wahrscheinlichkeit eines erfolgreichen Ergebnisses, p, parametrisiert. Es wird nicht durch die Zahl n, die Anzahl der Wurftests, parametrisiert, da die Anzahl der fehlgeschlagenen Tests genau das Ergebnis ist.Wenn die Binomialverteilung „Wie viele Erfolge“ lautet, lautet die geometrische Verteilung „Wie viele Misserfolge vor dem Erfolg?“
Die negative Binomialverteilung ist eine einfache Verallgemeinerung der vorherigen. Dies ist die Anzahl der Fehlschläge, bevor es r, nicht 1, Erfolge gibt. Daher wird es durch dieses r weiter parametrisiert. Es wird manchmal als die Anzahl von Erfolgen gegenüber Misserfolgen beschrieben. Aber wie mein Lebensberater sagt: „Sie entscheiden, was Erfolg und was Misserfolg ist“, also ist es dasselbe, solange Sie bedenken, dass die Wahrscheinlichkeit p auch die richtige Wahrscheinlichkeit für Erfolg bzw. Misserfolg sein sollte.
Wenn Sie einen Witz brauchen, um die Spannung zu lockern, können Sie erwähnen, dass die Binomialverteilung und die hypergeometrische Verteilung ein offensichtliches Paar sind, aber die geometrische und die negative Binomialverteilung sind auch ziemlich ähnlich, und sagen Sie dann: „Na, wer nennt das alles so?“ ”
Exponential und Weibula
Nochmals zu den Anrufen beim technischen Support: Wie lange dauert es bis zum nächsten Anruf? Die Verteilung dieser Wartezeit scheint geometrisch zu sein, denn jede Sekunde, bis niemand anruft, ist wie ein Misserfolg, bis die Sekunde, bis der Anruf endlich erfolgt. Die Anzahl der Ausfälle entspricht der Anzahl der Sekunden, bis niemand anruft, und zwar so praktisch Zeit bis zum nächsten Anruf, aber „praktisch“ reicht uns nicht. Der Punkt ist, dass diese Zeit die Summe ganzer Sekunden ist und es daher nicht möglich ist, die Wartezeit innerhalb dieser Sekunde vor dem eigentlichen Anruf zu zählen.Nun, wir bewegen uns nach wie vor an der Grenze der geometrischen Verteilung, was die Zeitanteile betrifft – und voilà. Wir erhalten eine Exponentialverteilung, die die Zeit vor dem Anruf genau beschreibt. Dies ist eine kontinuierliche Verteilung, die erste unserer Art, da das Ergebnis nicht unbedingt in ganzen Sekunden erfolgt. Wie die Poisson-Verteilung wird sie durch die Intensität λ parametrisiert.
Poissons „Wie viele Ereignisse in der Zeit?“ bekräftigt den Zusammenhang zwischen dem Binomial und dem Geometrischen. hängt mit der Exponentialfunktion „Wie lange dauert es bis zum Ereignis?“ zusammen. Wenn es Ereignisse gibt, deren Anzahl pro Zeiteinheit der Poisson-Verteilung folgt, dann folgt die Zeit zwischen ihnen der Exponentialverteilung mit demselben Parameter λ. Diese Übereinstimmung zwischen den beiden Verteilungen muss beachtet werden, wenn eine von ihnen diskutiert wird.
Die Exponentialverteilung sollte Ihnen in den Sinn kommen, wenn Sie über die „Zeit bis zum Ereignis“ nachdenken, vielleicht über die „Zeit bis zum Scheitern“. Tatsächlich ist dies eine so wichtige Situation, dass es allgemeinere Verteilungen zur Beschreibung der MTBF gibt, wie beispielsweise die Weibull-Verteilung. Während die Exponentialverteilung geeignet ist, wenn beispielsweise die Verschleißrate oder Ausfallrate konstant ist, kann die Weibull-Verteilung die Ausfallraten modellieren, die mit der Zeit ansteigen (oder abnehmen). Exponential ist im Allgemeinen ein Sonderfall.
Denken Sie an „Weibull“, wenn Sie über MTBF sprechen.
Normal, Lognormal, Student-t und Chi-Quadrat
Die Normalverteilung oder Gaußsche Verteilung ist wahrscheinlich eine der wichtigsten. Seine glockenförmige Form ist sofort erkennbar. Dies ist beispielsweise eine besonders merkwürdige Entität, die sich überall manifestiert, selbst aus den scheinbar einfachsten Quellen. Nehmen Sie eine Reihe von Werten, die derselben Verteilung folgen – irgendeinen! - und falte sie. Die Verteilung ihrer Summe folgt (näherungsweise) einer Normalverteilung. Je mehr Dinge addiert werden, desto näher entspricht ihre Summe der Normalverteilung (der Haken: Die Verteilung der Terme muss vorhersehbar und unabhängig sein, sie tendiert nur zur Normalverteilung). Dass dies trotz der ursprünglichen Verbreitung zutrifft, ist erstaunlich.Notiz Übersetzung
Ich war überrascht, dass der Autor nicht über die Notwendigkeit einer vergleichbaren Skala summierter Verteilungen schreibt: Wenn eine die anderen deutlich dominiert, wird die Konvergenz extrem schlecht sein. Und im Allgemeinen ist eine absolute gegenseitige Unabhängigkeit nicht erforderlich; eine schwache Abhängigkeit reicht aus.
Na ja, wahrscheinlich gut für Partys, wie er schrieb.
Dies nennt man den „Zentralen Grenzwertsatz“, und Sie müssen wissen, was er ist, warum er so heißt und was er bedeutet, sonst werden Sie sofort lachen.
In seinem Kontext ist „normal“ mit allen Verteilungen verbunden. Obwohl es im Grunde genommen mit der Verteilung aller möglichen Beträge verbunden ist. Die Summe der Bernoulli-Versuche folgt einer Binomialverteilung, und mit zunehmender Anzahl der Versuche nähert sich diese Binomialverteilung einer Normalverteilung an. Ebenso ist ihr Cousin die hypergeometrische Verteilung. Auch die Poisson-Verteilung – die Grenzform des Binomials – nähert sich mit zunehmendem Intensitätsparameter der Normalverteilung an.
Ergebnisse, die einer Lognormalverteilung folgen, erzeugen Werte, deren Logarithmus normalverteilt ist. Oder anders ausgedrückt: Der Exponent eines normalverteilten Wertes ist logarithmisch normalverteilt. Wenn die Summen normalverteilt sind, dann denken Sie daran, dass die Produkte logarithmisch normalverteilt sind.
Die Student-t-Verteilung ist die Grundlage des t-Tests, den viele Nicht-Statistiker in anderen Bereichen studieren. Es wird verwendet, um Annahmen über den Mittelwert einer Normalverteilung zu treffen, und tendiert auch zur Normalverteilung, wenn ihr Parameter zunimmt. Ein charakteristisches Merkmal der t-Verteilung sind ihre Enden, die dicker sind als die der Normalverteilung.
Wenn der fette Witz Ihren Nachbarn nicht genug beeindruckt hat, fahren Sie mit einer ziemlich lustigen Geschichte über Bier fort. Vor mehr als 100 Jahren nutzte Guinness Statistiken, um sein Stout zu verbessern. Dann erfand William Seely Gosset eine völlig neue statistische Theorie für einen verbesserten Gerstenanbau. Gossett überzeugte seinen Chef, dass andere Brauer nicht verstehen würden, wie sie seine Ideen nutzen sollten, und erhielt die Erlaubnis zur Veröffentlichung, allerdings unter dem Pseudonym „Student“. Gossets berühmteste Errungenschaft ist genau diese T-Distribution, die sozusagen nach ihm benannt ist.
Schließlich ist die Chi-Quadrat-Verteilung die Verteilung der Quadratsummen normalverteilter Werte. Der Chi-Quadrat-Test basiert auf dieser Verteilung, die ihrerseits auf der Summe der Quadrate der Differenzen basiert, die normalverteilt sein sollten.
Gamma und Beta
Wenn Sie an diesem Punkt bereits begonnen haben, über Chi-Quadrat-Themen zu sprechen, beginnt das Gespräch ernsthaft. Möglicherweise sprechen Sie bereits mit echten Statistikern, und Sie sollten sich wahrscheinlich schon jetzt zurückziehen, weil Dinge wie die Gammaverteilung zur Sprache kommen könnten. Dies ist eine Verallgemeinerung Und exponentiell Und Chi-Quadrat-Verteilung. Sie wird wie die Exponentialverteilung für komplexe Wartezeitmodelle verwendet. Beispielsweise erscheint eine Gammaverteilung, wenn die Zeit bis zu den nächsten n Ereignissen simuliert wird. Im maschinellen Lernen erscheint sie als „Adjungierte-Prior-Verteilung“ zu einigen anderen Verteilungen.Sprechen Sie nicht über diese konjugierten Verteilungen, aber wenn es sein muss, vergessen Sie nicht, über die Beta-Verteilung zu sprechen, da es sich um das Konjugat vor den meisten der hier erwähnten Verteilungen handelt. Datenwissenschaftler sind sich sicher, dass es genau dafür gemacht wurde. Erwähnen Sie dies beiläufig und gehen Sie zur Tür.
Der Anfang der Weisheit
Über Wahrscheinlichkeitsverteilungen kann man nicht viel wissen. Wirklich Interessierte können dieser äußerst detaillierten Karte aller Wahrscheinlichkeitsverteilungen Tags hinzufügenDie Wahrscheinlichkeitsverteilung ist ein Wahrscheinlichkeitsmaß für einen messbaren Raum.
Sei W eine nichtleere Menge beliebiger Natur und Ƒ -s- Algebra auf W, d A Î Ƒ set = W\ A gehört wieder dazu Ƒ und wenn A 1 , A 2 ,…О Ƒ , Das Ƒ Und Ƒ ). Paar (W, Ƒ ) wird als messbarer Raum bezeichnet. Nichtnegative Funktion P( A), für alle definiert A Î Ƒ , heißt Wahrscheinlichkeitsmaß, Wahrscheinlichkeit, P. Wahrscheinlichkeiten oder einfach P., wenn P(W) = 1 und P abzählbar additiv ist, also für jede Folge A 1 , A 2 ,…О Ƒ so dass A i ∩ Ein j= Æ für alle ich ¹ J, die Gleichheit P() = P( A i). Drei (W, Ƒ , P) heißt Wahrscheinlichkeitsraum. Der Wahrscheinlichkeitsraum ist das ursprüngliche Konzept der von A.N. vorgeschlagenen axiomatischen Wahrscheinlichkeitstheorie. Kolmogorov in den frühen 1930er Jahren.
Auf jedem Wahrscheinlichkeitsraum kann man (reale) messbare Funktionen berücksichtigen X = X(w), wÎW, das heißt, funktioniert so, dass (w: X(w)О B} Î Ƒ für jede Borel-Teilmenge B echte Linie R. Messbarkeit einer Funktion X ist äquivalent zu (w: X(w)< X} Î Ƒ für jeden echten X. Messbare Funktionen werden Zufallsvariablen genannt. Jede Zufallsvariable X, definiert auf dem Wahrscheinlichkeitsraum (W, Ƒ , P), erzeugt P.-Wahrscheinlichkeiten
P X
(B) = P( XÎ B) = P((w: X(w)О B}), B Î Ɓ
,
auf messbarem Raum ( R,
Ɓ
), Wo Ɓ
R und die Verteilungsfunktion
F X(X) = P( X < X) = P((w: X(w)< X}), -¥ < X <¥,
die als Wahrscheinlichkeit Wahrscheinlichkeit und Verteilungsfunktion einer Zufallsvariablen bezeichnet werden X.
Verteilungsfunktion F Jede Zufallsvariable hat die Eigenschaften
1. F(X) nicht abnehmend,
2. F(- ¥) = 0, F(¥) = 1,
3. F(X) bleibt an jedem Punkt stetig X.
Manchmal in der Definition der Verteilungsfunktion die Ungleichung< заменяется неравенством £; в этом случае функция распределения является непрерывной справа. В содержательных утверждениях теории вероятностей не важно, непрерывна функция распределения слева или справа, важны лишь положения ее точек разрыва X(falls vorhanden) und Inkrementgrößen F(X+0) - F(X-0) an diesen Punkten; Wenn F X, dann ist dieses Inkrement P( X = X).
Jede Funktion F, mit den Eigenschaften 1. - 3. wird als Verteilungsfunktion bezeichnet. Korrespondenz zwischen Verteilungen auf ( R, Ɓ ) und Verteilungsfunktionen sind eins zu eins. Für jedes R. P An ( R, Ɓ ) seine Verteilungsfunktion wird durch die Gleichheit bestimmt F(X) = P((-¥, X)), -¥ < X <¥, а для любой функции распределения F entsprechend R. P ist auf der Algebra £ von Mengen definiert, die aus Vereinigungen einer endlichen Anzahl disjunkter Intervalle bestehen F 1 (X) steigt linear von 0 auf 1. Um die Funktion zu konstruieren F 2 (X) Das Segment ist in Segment, Intervall (1/3, 2/3) und Segment unterteilt. Funktion F 2 (X) auf dem Intervall (1/3, 2/3) ist gleich 1/2 und steigt linear von 0 auf 1/2 und von 1/2 auf 1 auf den Segmenten bzw. an. Dieser Vorgang läuft weiter und die Funktion Fn+1 wird mit der folgenden Funktionstransformation erhalten Fn, N³ 2. In Intervallen, in denen die Funktion Fn(X) ist konstant, Fn +1 (X) fällt zusammen mit Fn(X). Jedes Segment, in dem die Funktion Fn(X) steigt linear von an A Vor B ist in Segment , Intervall (a + (a - b)/3, a + 2(b - a)/3) und Segment unterteilt. Im angegebenen Intervall Fn +1 (X) ist gleich ( A + B)/2 und auf den angegebenen Segmenten Fn +1 (X) steigt linear von an A Vor ( A + B)/2und von ( A + B)/2 bis B jeweils. Für jeweils 0 £ X 1-£-Sequenz Fn(X), N= 1, 2,..., konvergiert gegen eine Zahl F(X). Reihenfolge der Verteilungsfunktionen Fn, N= 1, 2,..., ist gleichstetig, daher die Grenzverteilungsfunktion F(X) ist stetig. Diese Funktion ist in einer abzählbaren Menge von Intervallen konstant (die Werte der Funktion sind in verschiedenen Intervallen unterschiedlich), in denen es keine Wachstumspunkte gibt, und die Gesamtlänge dieser Intervalle beträgt 1. Daher ist das Lebesgue-Maß der Zus. einstellen F ist gleich Null, das heißt F Singular.
Jede Verteilungsfunktion kann dargestellt werden als:
F(X) = P ac F Wechselstrom ( X) + P D F D ( X) + P S F S ( X),
Wo F Wechselstrom, F d und F s ist absolut stetige, diskrete und singuläre Verteilungsfunktionen und die Summe nichtnegativer Zahlen P Wechselstrom, P d und p s ist gleich eins. Diese Darstellung nennt man Lebesgue-Entwicklung und die Funktionen F Wechselstrom, F d und F s - Zersetzungskomponenten.
Die Verteilungsfunktion heißt symmetrisch wenn F(-X) = 1 - F(X+ 0) für
X> 0. Wenn eine symmetrische Verteilungsfunktion absolut stetig ist, dann ist ihre Dichte eine gerade Funktion. Wenn die Zufallsvariable X hat eine symmetrische Verteilung, dann die Zufallsvariablen X Und - X gleichmäßig verteilt. Wenn die symmetrische Verteilungsfunktion F(X) ist dann stetig bei Null F(0) = 1/2.
Zu den absolut stetigen Regeln, die in der Wahrscheinlichkeitstheorie häufig verwendet werden, gehören einheitliche Regeln, Normalregeln (Gauß-Regeln), Exponentialregeln und Cauchy-Regeln.
R. heißt einheitlich im Intervall ( A, B) (oder auf dem Segment [ A, B] oder in Abständen [ A, B) Und ( A, B]), wenn seine Dichte konstant ist (und gleich 1/( B - A)) An ( A, B) und ist außerhalb von ( A, B). Am häufigsten wird eine Gleichverteilung auf (0, 1) verwendet, ihre Verteilungsfunktion F(X) ist gleich Null bei X£ 0, gleich eins bei X>1 und F(X) = X bei 0< X£ 1. Eine einheitliche Zufallsvariable auf (0, 1) hat eine Zufallsvariable X(w) = w auf einem Wahrscheinlichkeitsraum bestehend aus dem Intervall (0, 1), einer Menge von Borel-Teilmengen dieses Intervalls und dem Lebesgue-Maß. Dieser Wahrscheinlichkeitsraum entspricht dem Experiment „einen Punkt w zufällig auf das Intervall (0, 1) werfen“, wobei das Wort „zufällig“ Gleichheit („Chancengleichheit“) aller Punkte aus (0, 1) bedeutet. Wenn auf dem Wahrscheinlichkeitsraum (W, Ƒ , P) es gibt eine Zufallsvariable X mit einer gleichmäßigen Verteilung auf (0, 1), dann darauf für jede Verteilungsfunktion F es gibt eine Zufallsvariable Y, für die die Verteilungsfunktion F Y fällt zusammen mit F. Zum Beispiel die Verteilungsfunktion einer Zufallsvariablen Y = F -1 (X) fällt zusammen mit F. Hier F -1 (j) = inf( X: F(X) > j}, 0 < j < 1; если функция F(X) ist dann auf der gesamten reellen Linie stetig und streng monoton F-1 - Umkehrfunktion F.
Normales R. mit Parametern ( A, s 2), -¥< A < ¥, s 2 >0, genannt R. mit Dichte, -¥< X < ¥. Чаще всего используется нормальное Р. с параметрами A= 0 und s 2 = 1, was als Standardnormal R bezeichnet wird., seine Verteilungsfunktion F( X) wird nicht durch Superpositionen elementarer Funktionen ausgedrückt und wir müssen ihre Integraldarstellung F( X) =, -¥ < X < ¥. Для фунции распределения F(X) Es wurden detaillierte Tabellen zusammengestellt, die vor dem Erscheinen der modernen Computertechnologie notwendig waren (Werte der Funktion F( X) können auch über spezielle Tabellen ermittelt werden. Funktionen erf( X)), Werte F( X) Für X> 0 kann durch die Summe der Reihen ermittelt werden
,
und für X < 0 можно воспользоваться симметричностью F(X). Normalverteilungsfunktionswerte mit Parametern A und s 2 kann aus der Tatsache erhalten werden, dass es mit F(( X - A)/S). Wenn X 1 und X 2 unabhängige Normalverteilung mit Parametern A 1 , s 1 2 und A 2 , s 2 2 Zufallsvariablen, dann die Verteilung ihrer Summe X 1 + X 2 ist auch mit Parametern in Ordnung A= A 1 + A 2 und s 2 = s 1 2 + s 2 2 . Die Aussage trifft in gewissem Sinne auch auf das Gegenteil zu: Wenn eine Zufallsvariable vorliegt X normalverteilt mit Parametern A und s 2 und
X = X 1 + X 2 wo X 1 und X 2 sind also unabhängige Zufallsvariablen, die keine Konstanten sind X 1 und X 2 haben Normalverteilungen (Satz von Cramer). Optionen A 1 , s 1 2 und A 2 , s 2 2 Verteilungen normaler Zufallsvariablen X 1 und X 2 im Zusammenhang mit A und s 2 durch die oben angegebenen Gleichungen. Die Standardnormalverteilung ist ein Grenzwert im zentralen Grenzwertsatz.
Die Exponentialverteilung ist eine Verteilung mit Dichte P(X) = 0 bei X < 0 и P(X) = l e- l X bei X³ 0, wobei l > 0 ein Parameter ist, seine Verteilungsfunktion F(X) = 0 bei X£0 und F(X) = 1 - e- l X bei X> 0 (manchmal werden exponentielle Parameter verwendet, die sich von den angegebenen durch eine Verschiebung entlang der reellen Achse unterscheiden). Dieses R. hat eine Eigenschaft, die Abwesenheit von Nachwirkung genannt wird: wenn X ist eine Zufallsvariable mit exponentiellem R., dann für jedes positive X Und T
P( X > X + T | X > X) = P( X > T).
Wenn X Ist die Betriebszeit eines Geräts vor dem Ausfall, dann bedeutet das Ausbleiben einer Nachwirkung, dass die Wahrscheinlichkeit groß ist, dass das Gerät, das zum Zeitpunkt 0 eingeschaltet wurde, erst dann ausfällt X + T vorausgesetzt, er weigerte sich bis zum jetzigen Zeitpunkt nicht X, hängt nicht davon ab X. Diese Eigenschaft wird als fehlende „Alterung“ interpretiert. Das Fehlen von Nachwirkungen ist eine charakteristische Eigenschaft der Exponentialverteilung: In der Klasse der absolut stetigen Verteilungen gilt die obige Gleichheit nur für die Exponentialverteilung (mit einem Parameter l > 0). Exponentielles R. erscheint als Grenzwert R. im Minimalschema. Lassen X 1 , X 2 ,… – nichtnegative unabhängige, identisch verteilte Zufallsvariablen und für ihre gemeinsame Verteilungsfunktion F Punkt 0 ist der Wachstumspunkt. Dann um N®¥ Verteilungen von Zufallsvariablen YN= min( X 1 ,…, X n) konvergieren schwach gegen eine entartete Verteilung mit einem einzigen Wachstumspunkt 0 (dies ist ein Analogon zum Gesetz der großen Zahlen). Nehmen wir zusätzlich an, dass für ein e > 0 die Verteilungsfunktion gilt F(X) auf dem Intervall (0, e) lässt die Darstellung zu und P(u)®l bei u¯ 0, dann die Verteilungsfunktionen der Zufallsvariablen Z N = N
Mindest( X 1 ,…, X n) bei N®¥ gleichmäßig über -¥< X < ¥ сходятся к экспоненциальной функции распределения с параметром l (это - аналог центральной предельной теоремы).
R. Cauchy heißt R. mit Dichte P(X) = 1/(p(1 + X 2)), -¥< X < ¥, его функция рас-пределения F(X) = (arctg X+ p/2)/p. Dieser R. erschien 1832 im Werk von S. Poisson im Zusammenhang mit der Lösung des folgenden Problems: Gibt es unabhängige identisch verteilte Zufallsvariablen? X 1 , X 2 ,... so dass das arithmetische Mittel ( X 1 + … + X n)/N bei jedem N haben das gleiche R wie jede der Zufallsvariablen X 1 , X 2 ,...? S. Poisson entdeckte, dass Zufallsvariablen mit der angegebenen Dichte diese Eigenschaft besitzen. Für diese Zufallsvariablen gilt die Aussage des Gesetzes der großen Zahlen nicht, in dem arithmetische Mittel ( X 1 +…+ X n)/N mit Wachstum N degenerieren. Dies widerspricht jedoch nicht dem Gesetz der großen Zahlen, da es Beschränkungen für die Verteilungen der ursprünglichen Zufallsvariablen auferlegt, die für die angegebene Verteilung nicht erfüllt sind (für diese Verteilung gibt es Absolutmomente aller positiven Ordnungen kleiner als Eins, aber die (mathematische Erwartung existiert nicht). In den Werken von O. Cauchy tauchte 1853 R. auf, der seinen Namen trug. R. Cauchy ist verwandt X/Y unabhängige Zufallsvariablen mit Standardnormal P.
Zu den diskreten Variablen, die in der Wahrscheinlichkeitstheorie häufig verwendet werden, gehören R. Bernoulli, Binomial R. und R. Poisson.
R. Bernoulli nennt jede Verteilung mit zwei Wachstumspunkten. Die am häufigsten verwendete Zufallsvariable ist R. X, wobei die Werte 0 und 1 mit Wahrscheinlichkeiten angenommen werden
Q = 1 - P Und P jeweils mit 0< P < 1 - параметр. Первые формы закона больших чисел и центральной предельной теоремы были получены для случайных величин, имею-щих Р. Бернулли. Если на вероятностном пространстве (W, Ƒ
, P) es gibt eine Folge X 1 , X 2,... unabhängige Zufallsvariablen, die die Werte 0 und 1 mit Wahrscheinlichkeiten von jeweils 1/2 annehmen, dann existiert auf diesem Wahrscheinlichkeitsraum eine Zufallsvariable mit einheitlichem R auf (0, 1). Insbesondere ist die Zufallsvariable gleichmäßig auf (0, 1) verteilt.
Binomial R. mit Parametern N Und P, N- natürlich, 0< P < 1, называется Р., с точками роста 0, 1,..., N, in dem die Wahrscheinlichkeiten konzentriert sind C n k p k q n-k, k = 0, 1,…, N,
Q = 1 - P. Es ist R. Betrag N unabhängige Zufallsvariablen mit R. Bernoulli mit Wachstumspunkten 0 und 1, in denen die Wahrscheinlichkeiten konzentriert sind Q Und P. Das Studium dieser Verteilung führte J. Bernoulli zur Entdeckung des Gesetzes der großen Zahlen und A. Moivre zur Entdeckung des zentralen Grenzwertsatzes.
Eine Poisson-Formel nennt man eine Formel, deren Träger eine Folge von Punkten 0, 1,... ist, in denen die Wahrscheinlichkeiten l konzentriert sind k e-l/ k!, k= 0, 1,…, wobei l > 0 ein Parameter ist. Die Summe zweier unabhängiger Zufallsvariablen mit einem R. Poisson mit den Parametern l und m hat wiederum einen R. Poisson mit dem Parameter l + m. R. Poisson ist der Grenzwert für R. Bernoulli mit Parametern N Und P = P(N) bei N®¥ wenn N Und P durch die Relation verbunden n.p.®l bei N®¥ (Satz von Poisson). Wenn die Sequenz 0 ist< T 1 < T 2 < T 3 <… есть последовательность моментов времени, в которые происходят некоторые события (так. наз поток событий) и величины T 1 , T 2 -T 1 , T 3 - T 2 ,... sind unabhängige, identisch verteilte Zufallsvariablen und ihr gemeinsames R. ist exponentiell mit Parameter l > 0, dann ist die Zufallsvariable Xt, gleich der Anzahl der Ereignisse, die im Intervall (0, T), hat R. Poisson mit Parameter.l T(Ein solcher Fluss wird Poisson genannt).
Der Begriff R lässt sich vielfältig verallgemeinern; insbesondere erstreckt er sich auf den mehrdimensionalen Fall und auf algebraische Strukturen.
Die Wahrscheinlichkeitstheorie ist ein Zweig der Mathematik, der die Muster zufälliger Phänomene untersucht: Zufallsereignisse, Zufallsvariablen, ihre Eigenschaften und Operationen auf ihnen.
Lange Zeit gab es in der Wahrscheinlichkeitstheorie keine klare Definition. Es wurde erst 1929 formuliert. Die Entstehung der Wahrscheinlichkeitstheorie als Wissenschaft geht auf das Mittelalter und die ersten Versuche einer mathematischen Analyse des Glücksspiels (Flocken, Würfel, Roulette) zurück. Die französischen Mathematiker des 17. Jahrhunderts Blaise Pascal und Pierre Fermat entdeckten bei der Untersuchung der Gewinnvorhersage beim Glücksspiel die ersten Wahrscheinlichkeitsmuster, die beim Würfeln entstehen.
Die Wahrscheinlichkeitstheorie entstand als Wissenschaft aus der Überzeugung, dass zufällige Massenereignisse auf bestimmten Mustern beruhen. Die Wahrscheinlichkeitstheorie untersucht diese Muster.
Die Wahrscheinlichkeitstheorie befasst sich mit der Untersuchung von Ereignissen, deren Eintritt nicht mit Sicherheit bekannt ist. Damit können Sie den Grad der Wahrscheinlichkeit des Eintretens einiger Ereignisse im Vergleich zu anderen beurteilen.
Zum Beispiel: Es ist unmöglich, das Ergebnis von „Kopf“ oder „Zahl“ als Ergebnis eines Münzwurfs eindeutig zu bestimmen, aber bei wiederholtem Werfen erscheint ungefähr die gleiche Anzahl von „Kopf“ und „Zahl“, was bedeutet, dass die Die Wahrscheinlichkeit, dass „Kopf“ oder „Zahl“ fällt, beträgt 50 %.
Prüfen in diesem Fall spricht man von der Umsetzung einer bestimmten Reihe von Bedingungen, also in diesem Fall vom Werfen einer Münze. Die Herausforderung kann unbegrenzt oft gespielt werden. In diesem Fall umfasst die Bedingungsmenge Zufallsfaktoren.
Das Testergebnis ist Ereignis. Das Ereignis findet statt:
- Zuverlässig (tritt immer als Ergebnis von Tests auf).
- Unmöglich (passiert nie).
- Zufällig (kann als Ergebnis des Tests auftreten oder auch nicht).
Wenn zum Beispiel eine Münze geworfen wird, kommt es zu einem unmöglichen Ereignis – die Münze landet auf ihrer Kante, zu einem zufälligen Ereignis – dem Erscheinen von „Kopf“ oder „Zahl“. Das konkrete Testergebnis wird aufgerufen elementares Ereignis. Als Ergebnis des Tests treten nur elementare Ereignisse auf. Die Menge aller möglichen, unterschiedlichen, spezifischen Testergebnisse heißt Raum elementarer Ereignisse.
Grundbegriffe der Theorie
Wahrscheinlichkeit- der Grad der Wahrscheinlichkeit des Eintretens eines Ereignisses. Wenn die Gründe für das tatsächliche Eintreten eines möglichen Ereignisses die gegenteiligen Gründe überwiegen, wird dieses Ereignis als wahrscheinlich bezeichnet, andernfalls als unwahrscheinlich oder unwahrscheinlich.
Zufälliger Wert- Dies ist eine Größe, die aufgrund von Tests den einen oder anderen Wert annehmen kann, und es ist nicht im Voraus bekannt, welcher. Zum Beispiel: Anzahl pro Feuerwache pro Tag, Anzahl der Treffer mit 10 Schüssen usw.
Zufallsvariablen können in zwei Kategorien unterteilt werden.
- Diskrete Zufallsvariable ist eine Größe, die als Ergebnis einer Prüfung mit einer bestimmten Wahrscheinlichkeit bestimmte Werte annehmen kann und so eine abzählbare Menge (eine Menge, deren Elemente nummeriert werden können) bildet. Diese Menge kann entweder endlich oder unendlich sein. Beispielsweise ist die Anzahl der Schüsse vor dem ersten Treffer auf das Ziel eine diskrete Zufallsvariable, denn Diese Größe kann unendlich viele, wenn auch abzählbare Werte annehmen.
- Kontinuierliche Zufallsvariable ist eine Größe, die jeden Wert aus einem endlichen oder unendlichen Intervall annehmen kann. Offensichtlich ist die Anzahl möglicher Werte einer kontinuierlichen Zufallsvariablen unendlich.
Wahrscheinlichkeitsraum- Konzept eingeführt von A.N. Kolmogorov in den 30er Jahren des 20. Jahrhunderts, um das Konzept der Wahrscheinlichkeit zu formalisieren, was zu einer raschen Entwicklung der Wahrscheinlichkeitstheorie als einer strengen mathematischen Disziplin führte.
Ein Wahrscheinlichkeitsraum ist ein Tripel (manchmal in spitzen Klammern eingeschlossen: , wobei
Dabei handelt es sich um eine beliebige Menge, deren Elemente elementare Ereignisse, Ergebnisse oder Punkte genannt werden;
- Sigma-Algebra von Teilmengen, die als (zufällige) Ereignisse bezeichnet werden;
- Wahrscheinlichkeitsmaß oder Wahrscheinlichkeit, d.h. Sigma-additives endliches Maß, so dass .
Satz von De Moivre-Laplace- einer der Grenzwertsätze der Wahrscheinlichkeitstheorie, der 1812 von Laplace aufgestellt wurde. Es besagt, dass die Anzahl der Erfolge bei wiederholter Wiederholung desselben Zufallsexperiments mit zwei möglichen Ausgängen annähernd normalverteilt ist. Damit können Sie einen ungefähren Wahrscheinlichkeitswert ermitteln.
Wenn für jeden der unabhängigen Versuche die Wahrscheinlichkeit des Auftretens eines zufälligen Ereignisses gleich () ist und der Anzahl der Versuche entspricht, in denen es tatsächlich auftritt, dann liegt die Wahrscheinlichkeit, dass die Ungleichung wahr ist, nahe (für große Werte) bei Wert des Laplace-Integrals.
Verteilungsfunktion in der Wahrscheinlichkeitstheorie- eine Funktion, die die Verteilung einer Zufallsvariablen oder eines Zufallsvektors charakterisiert; die Wahrscheinlichkeit, dass eine Zufallsvariable X einen Wert kleiner oder gleich x annimmt, wobei x eine beliebige reelle Zahl ist. Wenn bekannte Bedingungen erfüllt sind, bestimmt sie die Zufallsvariable vollständig.
Erwarteter Wert- der Durchschnittswert einer Zufallsvariablen (das ist die Wahrscheinlichkeitsverteilung einer Zufallsvariablen, die in der Wahrscheinlichkeitstheorie berücksichtigt wird). In der englischsprachigen Literatur wird es mit , im Russischen mit , bezeichnet. In der Statistik wird häufig die Notation verwendet.
Gegeben seien ein Wahrscheinlichkeitsraum und eine darauf definierte Zufallsvariable. Das ist per Definition eine messbare Funktion. Wenn es dann ein Lebesgue-Integral über den Raum gibt, wird es als mathematischer Erwartungswert oder Mittelwert bezeichnet und mit bezeichnet.

Varianz einer Zufallsvariablen- ein Maß für die Streuung einer bestimmten Zufallsvariablen, d. h. ihre Abweichung von der mathematischen Erwartung. Es wird in der russischen und ausländischen Literatur bezeichnet. In der Statistik wird häufig die Notation oder verwendet. Die Quadratwurzel der Varianz wird als Standardabweichung, Standardabweichung oder Standardspanne bezeichnet.
Sei eine Zufallsvariable, die auf einem Wahrscheinlichkeitsraum definiert ist. Dann
wobei das Symbol die mathematische Erwartung bezeichnet.
In der Wahrscheinlichkeitstheorie werden zwei zufällige Ereignisse genannt unabhängig, wenn das Eintreten eines von ihnen die Wahrscheinlichkeit des Eintretens des anderen nicht verändert. Ebenso werden zwei Zufallsvariablen aufgerufen abhängig, wenn der Wert eines von ihnen die Wahrscheinlichkeit der Werte des anderen beeinflusst.
Die einfachste Form des Gesetzes der großen Zahlen ist der Satz von Bernoulli, der besagt, dass, wenn die Wahrscheinlichkeit eines Ereignisses in allen Versuchen gleich ist, die Häufigkeit des Ereignisses mit zunehmender Anzahl der Versuche tendenziell zur Wahrscheinlichkeit des Ereignisses tendiert und hört auf, zufällig zu sein.
Das Gesetz der großen Zahlen in der Wahrscheinlichkeitstheorie besagt, dass das arithmetische Mittel einer endlichen Stichprobe aus einer festen Verteilung nahe am theoretischen Mittel dieser Verteilung liegt. Je nach Art der Konvergenz unterscheidet man zwischen dem schwachen Gesetz der großen Zahlen, bei dem die Konvergenz durch Wahrscheinlichkeit erfolgt, und dem starken Gesetz der großen Zahlen, bei dem die Konvergenz nahezu sicher ist.
Die allgemeine Bedeutung des Gesetzes der großen Zahlen besteht darin, dass die gemeinsame Wirkung einer großen Anzahl identischer und unabhängiger Zufallsfaktoren zu einem Ergebnis führt, das im Grenzfall nicht vom Zufall abhängt.
Auf dieser Eigenschaft basieren Methoden zur Wahrscheinlichkeitsschätzung basierend auf der Analyse endlicher Stichproben. Ein klares Beispiel ist die Prognose von Wahlergebnissen auf der Grundlage einer Wählerbefragung.
Zentrale Grenzwertsätze- eine Klasse von Sätzen in der Wahrscheinlichkeitstheorie, die besagen, dass die Summe einer ausreichend großen Anzahl schwach abhängiger Zufallsvariablen mit annähernd gleichen Skalen (keiner der Terme dominiert oder einen entscheidenden Beitrag zur Summe leistet) eine Verteilung nahe der Normalverteilung aufweist.
Da viele Zufallsvariablen in Anwendungen unter dem Einfluss mehrerer schwach abhängiger Zufallsfaktoren gebildet werden, gilt ihre Verteilung als normal. Dabei muss die Bedingung erfüllt sein, dass keiner der Faktoren dominant ist. Zentrale Grenzwertsätze rechtfertigen in diesen Fällen die Verwendung der Normalverteilung.
Was ist die Idee hinter probabilistischem Denken?Der erste, natürlichste Schritt des probabilistischen Denkens ist dieser: Wenn Sie eine Variable haben, die zufällig Werte annimmt, möchten Sie wissen, mit welcher Wahrscheinlichkeit diese Variable bestimmte Werte annimmt. Die Gesamtheit dieser Wahrscheinlichkeiten gibt die Wahrscheinlichkeitsverteilung an. Wenn Sie beispielsweise einen Würfel erhalten, können Sie dies tun Nehmen Sie a priori an, dass es mit gleichen Wahrscheinlichkeiten von 1/6 auf jede Kante fällt. Und dies geschieht unter der Voraussetzung, dass der Knochen symmetrisch ist. Wenn der Würfel asymmetrisch ist, können auf der Grundlage experimenteller Daten höhere Wahrscheinlichkeiten für diejenigen Gesichter bestimmt werden, die häufiger herausfallen, und niedrigere Wahrscheinlichkeiten für diejenigen Gesichter, die seltener herausfallen. Wenn ein Gesicht überhaupt nicht erscheint, kann ihm eine Wahrscheinlichkeit von 0 zugewiesen werden. Dies ist das einfachste Wahrscheinlichkeitsgesetz, mit dem sich die Ergebnisse eines Würfelwurfs beschreiben lassen. Natürlich ist dies ein äußerst einfaches Beispiel, aber ähnliche Probleme treten beispielsweise bei versicherungsmathematischen Berechnungen auf, wenn das tatsächliche Risiko bei der Ausstellung einer Versicherungspolice auf der Grundlage realer Daten berechnet wird.
In diesem Kapitel betrachten wir die Wahrscheinlichkeitsgesetze, die in der Praxis am häufigsten auftreten.
Diagramme dieser Verteilungen können in STATISTICA einfach erstellt werden.
Normalverteilung
Die normale Wahrscheinlichkeitsverteilung wird besonders häufig in der Statistik verwendet. Die Normalverteilung bietet ein gutes Modell für reale Phänomene, bei denen:
1) Es besteht eine starke Tendenz, dass sich Daten um ein Zentrum herum ansammeln.
2) positive und negative Abweichungen vom Zentrum sind gleich wahrscheinlich;
3) Die Abweichungshäufigkeit nimmt schnell ab, wenn die Abweichungen vom Zentrum groß werden.
Der der Normalverteilung zugrunde liegende Mechanismus, erklärt mit dem sogenannten zentralen Grenzwertsatz, lässt sich bildlich wie folgt beschreiben. Stellen Sie sich vor, Sie haben Pollenpartikel, die Sie zufällig in ein Glas Wasser fallen lassen. Wenn Sie ein einzelnes Teilchen unter dem Mikroskop betrachten, werden Sie ein erstaunliches Phänomen erkennen: Das Teilchen bewegt sich. Dies geschieht natürlich, weil sich Wassermoleküle bewegen und ihre Bewegung auf schwebende Pollenpartikel übertragen.
Doch wie genau entsteht Bewegung? Hier ist eine interessantere Frage. Und diese Bewegung ist sehr bizarr!
Es gibt unendlich viele unabhängige Einflüsse auf ein einzelnes Pollenpartikel in Form von Stößen von Wassermolekülen, die dazu führen, dass sich das Partikel auf einer sehr seltsamen Flugbahn bewegt. Unter dem Mikroskop ähnelt diese Bewegung einer wiederholt und chaotisch unterbrochenen Linie. Diese Knicke können nicht vorhergesagt werden, es gibt kein Muster in ihnen, das genau dem chaotischen Aufprall von Molekülen auf ein Teilchen entspricht. Ein suspendiertes Teilchen, das zu einem zufälligen Zeitpunkt den Aufprall eines Wassermoleküls erfahren hat, ändert die Richtung seiner Bewegung, bewegt sich dann eine Zeit lang durch Trägheit, fällt dann erneut unter den Aufprall des nächsten Moleküls und so weiter. Erstaunliches Billard erscheint in einem Glas Wasser!
Da die Bewegung von Molekülen eine zufällige Richtung und Geschwindigkeit hat, sind auch Größe und Richtung der Knicke in der Flugbahn völlig zufällig und unvorhersehbar. Dieses erstaunliche Phänomen namens Brownsche Bewegung, das im 19. Jahrhundert entdeckt wurde, gibt uns viel Anlass zum Nachdenken.
Wenn wir ein geeignetes System einführen und die Koordinaten des Teilchens zu bestimmten Zeitpunkten markieren, erhalten wir das Normalgesetz. Genauer gesagt gehorchen die durch molekulare Stöße verursachten Verschiebungen des Pollenpartikels dem Normalgesetz.
Zum ersten Mal wurde das Bewegungsgesetz eines solchen Teilchens, Brownian genannt, von A. Einstein auf physikalischer Ebene beschrieben. Lenzhevan entwickelte daraufhin einen einfacheren und intuitiveren Ansatz.
Mathematiker des 20. Jahrhunderts widmeten dieser Theorie ihre besten Seiten, und der erste Schritt wurde vor 300 Jahren getan, als die einfachste Version des zentralen Grenzwertsatzes entdeckt wurde.
In der Wahrscheinlichkeitstheorie der zentrale Grenzwertsatz, der ursprünglich in der Formulierung von Moivre und Laplace im 17. Jahrhundert als Weiterentwicklung des berühmten Gesetzes der großen Zahlen von J. Bernoulli (1654-1705) bekannt war (siehe J. Bernoulli (1713) , Ars Conjectandi), ist derzeit extrem entwickelt und hat seinen Höhepunkt erreicht. im modernen Invarianzprinzip, bei dessen Entstehung die russische Mathematikschule eine bedeutende Rolle spielte. In diesem Prinzip findet die Bewegung eines Brownschen Teilchens ihre strenge mathematische Erklärung.
Die Idee besteht darin, dass man bei der Summierung einer großen Anzahl unabhängiger Größen (Kollisionen von Molekülen auf Pollenpartikeln) unter bestimmten vernünftigen Bedingungen normalverteilte Größen erhält. Und dies geschieht unabhängig, also invariant, von der Verteilung der Anfangswerte. Mit anderen Worten: Wenn eine bestimmte Variable von vielen Faktoren beeinflusst wird, diese Einflüsse unabhängig voneinander sind, relativ klein sind und sich gegenseitig addieren, dann ist der resultierende Wert normalverteilt.
Beispielsweise bestimmen nahezu unendlich viele Faktoren das Gewicht eines Menschen (tausende Gene, Veranlagung, Krankheiten etc.). Daher würde man eine normale Gewichtsverteilung in einer Population aller Individuen erwarten.
Wenn Sie ein Finanzier sind und an der Börse tätig sind, dann kennen Sie natürlich Fälle, in denen sich Aktienkurse wie Brownsche Teilchen verhalten und chaotische Auswirkungen vieler Faktoren erfahren.

Formal wird die Normalverteilungsdichte wie folgt geschrieben:

wobei a und õ 2 die Parameter des Gesetzes sind, interpretiert als Mittelwert und Varianz einer bestimmten Zufallsvariablen (aufgrund der besonderen Rolle der Normalverteilung werden wir spezielle Symbole verwenden, um ihre Dichtefunktion und Verteilungsfunktion zu bezeichnen). Optisch gesehen ist das Normaldichtediagramm die berühmte glockenförmige Kurve.
Die entsprechende Verteilungsfunktion einer normalen Zufallsvariablen (a,õ 2) wird mit Ф(x; a,õ 2) bezeichnet und ist durch die Beziehung gegeben:

Das Normalgesetz mit den Parametern a = 0 und õ 2 = 1 heißt Standard.
Umkehrfunktion der Standardnormalverteilung, angewendet auf den Wert z, 0 Verwenden Sie den Wahrscheinlichkeitsrechner von STATISTICA, um z aus x und umgekehrt zu berechnen. Hauptmerkmale des Normalgesetzes: Mittelwert, Modus, Median: E=x mod =x med =a; Streuung: D=õ 2 ; Asymmetrie: Überschuss: Aus den Formeln geht hervor, dass die Normalverteilung durch zwei Parameter beschrieben wird: a – Mittelwert – Durchschnitt; õ – Standardabweichung – Standardabweichung, sprich: „Sigma“. Manchmal mit Standardabweichung heißt Standardabweichung, aber das ist bereits eine veraltete Terminologie. Hier sind einige nützliche Fakten zur Normalverteilung. Der Mittelwert bestimmt das Dichte-Standortmaß. Die Dichte einer Normalverteilung ist symmetrisch zum Mittelwert. Der Mittelwert einer Normalverteilung stimmt mit dem Median und dem Modus überein (siehe Diagramme). Dichte der Normalverteilung mit Varianz 1 und Mittelwert 1 Normalverteilungsdichte mit Mittelwert 0 und Varianz 0,01 Dichte der Normalverteilung mit Mittelwert 0 und Varianz 4 Mit zunehmender Streuung breitet sich die Dichte der Normalverteilung aus oder breitet sich entlang der OX-Achse aus; mit abnehmender Streuung zieht sie sich dagegen zusammen und konzentriert sich um einen Punkt – den Punkt des Maximalwerts, der mit dem Durchschnittswert zusammenfällt . Im Grenzfall der Varianz Null degeneriert die Zufallsvariable und nimmt einen einzigen Wert an, der dem Mittelwert entspricht. Es ist hilfreich, die 2- und 3-Sigma- oder 2- und 3-Standardabweichungsregeln zu kennen, die sich auf die Normalverteilung beziehen und in verschiedenen Anwendungen verwendet werden. Die Bedeutung dieser Regeln ist sehr einfach. Wenn wir vom Punkt des Durchschnitts oder, was dasselbe ist, vom Punkt der maximalen Dichte einer Normalverteilung aus zwei und drei Standardabweichungen (2- und 3-Sigma) nach rechts bzw. links setzen, dann ist die Die aus diesem Intervall berechnete Fläche unter dem Normaldichtediagramm entspricht 95,45 % bzw. 99,73 % der gesamten Fläche unter dem Diagramm (überprüfen Sie es mit dem STATISTICA-Wahrscheinlichkeitsrechner!). Mit anderen Worten lässt es sich wie folgt ausdrücken: 95,45 % und 99,73 % aller unabhängigen Beobachtungen in einer Normalpopulation, wie etwa Teilegröße oder Aktienpreis, liegen innerhalb von 2 und 3 Standardabweichungen vom Mittelwert. Gleichmäßige Verteilung Eine gleichmäßige Verteilung ist nützlich, wenn Variablen beschrieben werden, bei denen jeder Wert gleich wahrscheinlich ist, d. h. die Werte der Variablen sind gleichmäßig über einen bestimmten Bereich verteilt. Nachfolgend finden Sie die Formeln für die Dichte- und Verteilungsfunktion einer gleichmäßigen Zufallsvariablen, die Werte im Intervall [a, b] annimmt. Aus diesen Formeln lässt sich leicht verstehen, dass die Wahrscheinlichkeit, dass eine einheitliche Zufallsvariable Werte aus der Menge annimmt, ansteigt [c, d] [a, b], gleich (d – c)/(b – a). Lasst uns a=0,b=1. Unten sehen Sie ein Diagramm einer gleichmäßigen Wahrscheinlichkeitsdichte, die auf dem Segment zentriert ist. Numerische Merkmale des einheitlichen Gesetzes: Exponentialverteilung Es ereignen sich Ereignisse, die man im alltäglichen Sprachgebrauch als selten bezeichnen kann. Wenn T die Zeit zwischen dem Auftreten seltener Ereignisse ist, die im Durchschnitt mit der Intensität X auftreten, dann ist der Wert Diese Verteilung hat eine sehr interessante Eigenschaft der Abwesenheit von Nachwirkungen, oder, wie man auch sagt, die Markov-Eigenschaft zu Ehren des berühmten russischen Mathematikers A. A. Markov, die wie folgt erklärt werden kann. Wenn die Verteilung zwischen den Zeitpunkten des Auftretens bestimmter Ereignisse indikativ ist, wird die Verteilung ab jedem Zeitpunkt gezählt t bis zum nächsten Ereignis hat ebenfalls eine Exponentialverteilung (mit dem gleichen Parameter). Mit anderen Worten: Bei einem Strom seltener Ereignisse ist die Wartezeit auf den nächsten Besucher immer exponentiell verteilt, unabhängig davon, wie lange Sie bereits auf ihn gewartet haben. Die Exponentialverteilung hängt mit der Poisson-Verteilung zusammen: In einem Einheitszeitintervall weist die Anzahl der Ereignisse, deren Intervalle unabhängig und exponentiell verteilt sind, eine Poisson-Verteilung auf. Wenn die Abstände zwischen den Besuchen vor Ort exponentiell verteilt sind, verteilt sich die Anzahl der Besuche, beispielsweise innerhalb einer Stunde, nach dem Poisson-Gesetz. Die Exponentialverteilung ist ein Sonderfall der Weibull-Verteilung. Wenn die Zeit nicht kontinuierlich, sondern diskret ist, dann ist die geometrische Verteilung ein Analogon der Exponentialverteilung. Die exponentielle Verteilungsdichte wird durch die Formel beschrieben: Diese Verteilung hat nur einen Parameter, der ihre Eigenschaften bestimmt. Das Diagramm der exponentiellen Verteilungsdichte sieht folgendermaßen aus: Grundlegende numerische Merkmale der Exponentialverteilung: Erlang-Verteilung Diese kontinuierliche Verteilung ist auf (0,1) zentriert und hat die Dichte: Erwartung und Varianz sind jeweils gleich Die Erlang-Verteilung ist nach A. Erlang benannt, der sie erstmals bei Problemen der Warteschlangen- und Telefontheorie verwendete. Eine Erlang-Verteilung mit den Parametern µ und n ist die Verteilung der Summe von n unabhängigen, identisch verteilten Zufallsvariablen, die jeweils eine Exponentialverteilung mit dem Parameter nµ aufweisen Bei Die n = 1-Erlang-Verteilung ist dieselbe wie die Exponential- oder Exponentialverteilung. Laplace-Verteilung Die Laplace-Dichtefunktion, auch Doppelexponentialfunktion genannt, wird beispielsweise zur Beschreibung der Fehlerverteilung in Regressionsmodellen verwendet. Wenn Sie sich das Diagramm dieser Verteilung ansehen, werden Sie sehen, dass sie aus zwei Exponentialverteilungen besteht, die symmetrisch zur OY-Achse sind. Wenn der Positionsparameter 0 ist, hat die Laplace-Verteilungsdichtefunktion die Form: Die wichtigsten numerischen Merkmale dieses Verteilungsgesetzes sind unter der Annahme, dass der Positionsparameter Null ist, wie folgt: Im Allgemeinen hat die Laplace-Verteilungsdichte die Form: a ist der Mittelwert der Verteilung; b – Skalenparameter; e - Euler-Zahl (2,71...). Gammaverteilung Die Dichte der Exponentialverteilung hat einen Modus am Punkt 0, was für praktische Anwendungen manchmal unpraktisch ist. In vielen Beispielen ist im Voraus bekannt, dass der Modus der betrachteten Zufallsvariablen ungleich 0 ist, beispielsweise weisen die Intervalle zwischen Kunden, die in einem E-Commerce-Shop ankommen oder eine Website besuchen, einen ausgeprägten Modus auf. Zur Modellierung solcher Ereignisse wird die Gammaverteilung verwendet. Die Gammaverteilungsdichte hat die Form: Dabei ist Г die Eulersche Г-Funktion, a > 0 der „Form“-Parameter und b > 0 der Skalenparameter. Im konkreten Fall haben wir die Erlang-Verteilung und die Exponentialverteilung. Hauptmerkmale der Gammaverteilung: Nachfolgend finden Sie zwei Gammadichtediagramme mit einem Skalenparameter von 1 und Formparametern von 3 und 5. Nützliche Eigenschaft der Gammaverteilung: die Summe einer beliebigen Anzahl unabhängiger gammaverteilter Zufallsvariablen (mit demselben Skalenparameter b) (a l ,b) + (a 2 ,b) + --- +(a n ,b) folgt ebenfalls der Gammaverteilung, jedoch mit den Parametern a 1 + a 2 + + a n und b. Lognormalverteilung Eine Zufallsvariable h heißt logarithmisch normal oder lognormal, wenn ihr natürlicher Logarithmus (lnh) dem Normalverteilungsgesetz unterliegt. Die Lognormalverteilung wird beispielsweise bei der Modellierung von Variablen wie Einkommen, Alter des Brautpaares oder zulässiger Abweichung vom Standard für Schadstoffe in Lebensmitteln verwendet. Also, wenn der Wert x hat eine Normalverteilung, dann ist der Wert y = e x hat eine Lognormalverteilung. Wenn Sie einen Normalwert in die Potenz eines Exponenten einsetzen, können Sie leicht verstehen, dass ein Lognormalwert das Ergebnis wiederholter Multiplikationen unabhängiger Variablen ist, genauso wie eine normale Zufallsvariable das Ergebnis wiederholter Summation ist. Die Lognormalverteilungsdichte hat die Form: Hauptmerkmale der Lognormalverteilung: Chi-Quadrat-Verteilung Die Summe der Quadrate von m unabhängigen Normalvariablen mit Mittelwert 0 und Varianz 1 weist eine Chi-Quadrat-Verteilung mit m Freiheitsgraden auf. Diese Verteilung wird am häufigsten in der Datenanalyse verwendet. Formal hat die Dichte der wohlquadratischen Verteilung mit m Freiheitsgraden die Form: Für negativ x-Dichte wird 0. Grundlegende numerische Merkmale der Chi-Quadrat-Verteilung: Das Dichtediagramm ist in der folgenden Abbildung dargestellt: Binomialverteilung Die Binomialverteilung ist die wichtigste diskrete Verteilung, die sich auf wenige Punkte konzentriert. Die Binomialverteilung weist diesen Punkten positive Wahrscheinlichkeiten zu. Damit unterscheidet sich die Binomialverteilung von kontinuierlichen Verteilungen (Normalverteilung, Chi-Quadrat usw.), die einzelnen ausgewählten Punkten Nullwahrscheinlichkeiten zuweisen und als kontinuierlich bezeichnet werden. Sie können die Binomialverteilung besser verstehen, indem Sie das folgende Spiel betrachten. Stellen Sie sich vor, Sie werfen eine Münze. Es besteht die Möglichkeit, dass das Wappen herausfällt p, und die Wahrscheinlichkeit, Köpfe zu landen, ist q = 1 – p (wir betrachten den allgemeinsten Fall, wenn die Münze asymmetrisch ist, beispielsweise einen verschobenen Schwerpunkt hat – es gibt ein Loch in der Münze). Die Landung eines Wappens gilt als Erfolg, die Landung eines Schwanzes hingegen als Misserfolg. Dann hat die Anzahl der gezogenen Köpfe (oder Zahlen) eine Binomialverteilung. Beachten Sie, dass die Berücksichtigung asymmetrischer Münzen oder unregelmäßiger Würfel von praktischem Interesse ist. Wie J. Neumann in seinem eleganten Buch „An Introductory Course in the Theory of Probability and Mathematical Statistics“ feststellte, vermutete man schon lange, dass die Häufigkeit der Punkte auf einem Würfel von den Eigenschaften des Würfels selbst abhängt und künstlich verändert werden kann. Archäologen entdeckten im Grab des Pharaos zwei Knochenpaare: „ehrliche“ – mit gleicher Wahrscheinlichkeit, dass alle Seiten herausfallen, und falsche – mit einer absichtlichen Verschiebung des Schwerpunkts, was die Wahrscheinlichkeit des Herausfallens von Sechsern erhöhte. Die Parameter der Binomialverteilung sind die Erfolgswahrscheinlichkeit p (q = 1 - p) und die Anzahl der Tests n. Die Binomialverteilung eignet sich zur Beschreibung der Verteilung binomialer Ereignisse, beispielsweise der Anzahl von Männern und Frauen in zufällig ausgewählten Unternehmen. Von besonderer Bedeutung ist die Verwendung der Binomialverteilung bei Spielproblemen. Die genaue Formel für die Erfolgswahrscheinlichkeit m in n Versuche wird wie folgt geschrieben: p-Erfolgswahrscheinlichkeit q ist gleich 1-p, q>=0, p+q==1 n- Anzahl der Tests, m =0,1...m Hauptmerkmale der Binomialverteilung: Der Graph dieser Verteilung für unterschiedliche Anzahl von Versuchen n und Erfolgswahrscheinlichkeiten p hat die Form: Die Binomialverteilung hängt mit der Normal- und der Poisson-Verteilung zusammen (siehe unten); Für bestimmte Parameterwerte und eine große Anzahl von Tests ergeben sich diese Verteilungen. Dies lässt sich mit STATISTICA leicht nachweisen. Betrachten Sie beispielsweise einen Graphen einer Binomialverteilung mit Parametern p = 0,7, n = 100 (siehe Abbildung), wir haben STATISTICA BASIC verwendet – Sie können sehen, dass die Grafik der Dichte einer Normalverteilung sehr ähnlich ist (das ist sie wirklich!). Binomialverteilungsdiagramm mit Parametern p=0,05, n=100 ist dem Poisson-Verteilungsdiagramm sehr ähnlich. Wie bereits erwähnt, entstand die Binomialverteilung aus Beobachtungen des einfachsten Glücksspiels – dem Werfen einer fairen Münze. In vielen Situationen dient dieses Modell als gute erste Näherung für komplexere Spiele und die Zufallsprozesse, die im Aktienhandel auftreten. Es ist bemerkenswert, dass die wesentlichen Merkmale vieler komplexer Prozesse anhand eines einfachen Binomialmodells verstanden werden können. Betrachten Sie beispielsweise die folgende Situation. Markieren wir den Verlust eines Wappens mit 1 und den Verlust eines Schwanzes mit minus 1 und addieren die Gewinne und Verluste zu aufeinanderfolgenden Zeitpunkten. Die Grafiken zeigen typische Flugbahnen eines solchen Spiels für 1.000 Würfe, für 5.000 Würfe und für 10.000 Würfe. Beachten Sie, wie lange die Flugbahn über oder unter Null liegt, d unvorbereiteter Geist, für den der Ausdruck „absolut faires Spiel“ wie ein Zauberspruch klingt. Obwohl das Spiel also in Bezug auf seine Bedingungen fair ist, ist das Verhalten einer typischen Flugbahn überhaupt nicht fair und zeigt kein Gleichgewicht! Natürlich ist diese Tatsache empirisch allen Spielern bekannt; damit ist eine Strategie verbunden, wenn der Spieler nicht mit dem Gewinn gehen darf, sondern gezwungen ist, weiterzuspielen. Betrachten wir die Anzahl der Würfe, bei denen ein Spieler gewinnt (Flugbahn über 0) und der zweite Spieler verliert (Flugbahn unter 0). Auf den ersten Blick scheint die Anzahl solcher Würfe ungefähr gleich zu sein. Allerdings (siehe das spannende Buch: Feller V. „Einführung in die Wahrscheinlichkeitstheorie und ihre Anwendungen.“ Moskau: Mir, 1984, S. 106) mit 10.000 Würfen einer idealen Münze (also für Bernoulli-Tests mit p = q = 0,5, n=10.000) übersteigt die Wahrscheinlichkeit, dass eine der Parteien bei mehr als 9.930 Gerichtsverfahren und die andere bei weniger als 70 in Führung liegt, 0,1. Überraschenderweise ist bei einem Spiel mit 10.000 fairen Münzwürfen die Wahrscheinlichkeit, dass die Führung höchstens 8 Mal wechselt, größer als 0,14, und die Wahrscheinlichkeit von mehr als 78 Führungswechseln beträgt etwa 0,12. Wir haben also eine paradoxe Situation: Bei einem symmetrischen Bernoulli-Spaziergang können die „Wellen“ im Diagramm zwischen aufeinanderfolgenden Rückkehren zum Nullpunkt (siehe Diagramme) erstaunlich lang sein. Damit hängt noch ein anderer Umstand zusammen, nämlich dass z T n /n (Bruchteil der Zeit, wenn sich der Graph über der x-Achse befindet) am wenigsten wahrscheinlich sind Werte nahe 1/2. Mathematiker entdeckten das sogenannte Arkussinusgesetz, nach dem für jede 0< а <1 вероятность неравенства
, где Т n - число шагов, в течение которых первый игрок находится в выигрыше, стремится к Arkussinusverteilung Diese kontinuierliche Verteilung ist auf dem Intervall (0, 1) zentriert und hat eine Dichte: Die Arkussinusverteilung ist mit einer zufälligen Wanderung verbunden. Dies ist die Verteilung des Zeitanteils, in dem der erste Spieler gewinnt, wenn er eine symmetrische Münze wirft, also eine Münze mit gleichen Wahrscheinlichkeiten Das S fällt auf Wappen und Frack. Auf andere Weise kann ein solches Spiel als Zufallswanderung eines Teilchens betrachtet werden, das, ausgehend von Null, mit gleicher Wahrscheinlichkeit einzelne Sprünge nach rechts oder nach links macht. Da Partikelsprünge – fallende Köpfe oder fallende Zahlen – gleichermaßen wahrscheinlich sind, wird ein solcher Spaziergang oft als symmetrisch bezeichnet. Wenn die Wahrscheinlichkeiten unterschiedlich wären, hätten wir einen asymmetrischen Spaziergang. Das Diagramm der Arkussinusverteilungsdichte ist in der folgenden Abbildung dargestellt: Am interessantesten ist die qualitative Interpretation der Grafik, aus der man überraschende Rückschlüsse auf die Sieges- und Niederlagenserie in einem fairen Spiel ziehen kann. Wenn Sie sich die Grafik ansehen, können Sie sehen, dass an diesem Punkt die minimale Dichte vorliegt 1/2. „Na und?!“ - du fragst. Doch wenn Sie über diese Beobachtung nachdenken, dann kennt Ihre Überraschung keine Grenzen! Es stellt sich heraus, dass das Spiel zwar als fair definiert wird, in Wirklichkeit aber nicht so fair ist, wie es auf den ersten Blick erscheinen mag. Symmetrische Zufallsbahnen, bei denen das Teilchen sowohl auf der positiven als auch auf der negativen Halbachse, also rechts oder links vom Nullpunkt, die gleiche Zeit verbringt, sind gerade am wenigsten wahrscheinlich. Wenn wir auf die Sprache der Spieler übergehen, können wir sagen, dass beim Werfen einer symmetrischen Münze Spiele am unwahrscheinlichsten sind, bei denen die Spieler gleich viel Zeit mit Gewinnen und Verlieren verbringen. Im Gegenteil, Spiele, bei denen die Wahrscheinlichkeit, dass ein Spieler gewinnt und der andere verliert, deutlich höher ist, ist am wahrscheinlichsten. Erstaunliches Paradoxon! Um die Wahrscheinlichkeit zu berechnen, dass der Bruchteil der Zeit t, in dem der erste Spieler gewinnt, zwischen liegt t1 bis t2, benötigt aus dem Verteilungsfunktionswert F(t2) Subtrahieren Sie den Wert der Verteilungsfunktion F(t1). Formal erhalten wir: P(t1 Basierend auf dieser Tatsache kann mit STATISTICA berechnet werden, dass das Teilchen bei 10.000 Schritten mehr als 9930 Mal mit einer Wahrscheinlichkeit von 0,1 auf der positiven Seite bleibt, d. h. grob gesagt wird eine solche Position mindestens in einem Fall beobachtet von zehn (obwohl es auf den ersten Blick absurd erscheint; siehe Yu. V. Prokhorovs bemerkenswerte Notiz „Bernoulli's Rambler“ in der Enzyklopädie „Probability and Mathematical Statistics“, S. 42-43, M.: Big Russian Encyclopedia, 1999 ). Negative Binomialverteilung Dies ist eine diskrete Verteilung, die ganzzahligen Punkten zugewiesen wird k = 0,1,2,... Wahrscheinlichkeiten: p k =P(X=k)=C k r+k-1 p r (l-p) k ", wobei 0<р<1,r>0.
Die negative Binomialverteilung findet sich in vielen Anwendungen. Gesamt r > 0, die negative Binomialverteilung wird als Verteilung der Wartezeit auf den r-ten „Erfolg“ in einem Bernoulli-Testschema mit der Wahrscheinlichkeit von „Erfolg“ interpretiert p ist beispielsweise die Anzahl der Würfe, die durchgeführt werden müssen, bevor das zweite Emblem gezogen wird. In diesem Fall wird es manchmal als Pascal-Verteilung bezeichnet und ist ein diskretes Analogon der Gamma-Verteilung. Bei r = 1 Die negative Binomialverteilung stimmt mit der geometrischen Verteilung überein. Wenn Y eine Zufallsvariable ist, die eine Poisson-Verteilung mit einem Zufallsparameter hat, der wiederum eine Gamma-Verteilung mit Dichte hat Dann hat U eine negative Binomialverteilung mit Parametern; Poisson-Verteilung Die Poisson-Verteilung wird manchmal auch als Verteilung seltener Ereignisse bezeichnet. Beispiele für nach dem Poissonschen Gesetz verteilte Variablen sind: die Anzahl der Unfälle, die Anzahl der Fehler im Produktionsprozess usw. Die Poisson-Verteilung wird durch die Formel definiert: Hauptmerkmale einer Poisson-Zufallsvariablen: Die Poisson-Verteilung hängt mit der Exponentialverteilung und der Bernoulli-Verteilung zusammen. Wenn die Anzahl der Ereignisse eine Poisson-Verteilung aufweist, haben die Intervalle zwischen den Ereignissen eine Exponential- oder Exponentialverteilung. Poisson-Verteilungsdiagramm: Vergleichen Sie den Graphen der Poisson-Verteilung mit Parameter 5 mit dem Graphen der Bernoulli-Verteilung bei p=q=0,5,n=100. Sie werden sehen, dass die Diagramme sehr ähnlich sind. Im allgemeinen Fall gibt es das folgende Muster (siehe zum Beispiel das ausgezeichnete Buch: Shiryaev A.N. „Probability“. Moskau: Nauka, S. 76): Wenn in Bernoulli-Tests n große Werte annimmt und die Erfolgswahrscheinlichkeit / ? relativ klein ist, so dass die durchschnittliche Anzahl der Erfolge (Produkt und nar) weder klein noch groß ist, dann kann die Bernoulli-Verteilung mit den Parametern n, p durch die Poisson-Verteilung mit Parameter = np ersetzt werden. Die Poisson-Verteilung wird in der Praxis häufig verwendet, beispielsweise in Qualitätskontrollkarten als Verteilung seltener Ereignisse. Betrachten Sie als weiteres Beispiel das folgende Problem im Zusammenhang mit Telefonleitungen und aus der Praxis (siehe: Feller V. Einführung in die Wahrscheinlichkeitstheorie und ihre Anwendungen. Moskau: Mir, 1984, S. 205, sowie Molina E. S. (1935) Probability in Engineering, Elektrotechnik, 54, S. 423–427; Bell Telephone System Technical Publications Monograph B-854). Diese Aufgabe lässt sich leicht in eine moderne Sprache, beispielsweise in die Sprache des Mobilfunks, übersetzen, wozu interessierte Leser herzlich eingeladen sind. Das Problem wird wie folgt formuliert. Es soll zwei Telefonzentralen geben – A und B. Telefonzentrale A muss die Kommunikation zwischen 2.000 Teilnehmern und Vermittlungsstelle B ermöglichen. Die Qualität der Kommunikation muss so sein, dass nur 1 Anruf von 100 wartet, bis die Leitung frei ist. Die Frage ist: Wie viele Telefonleitungen müssen installiert werden, um die erforderliche Kommunikationsqualität sicherzustellen? Offensichtlich ist es dumm, 2.000 Zeilen zu erstellen, da viele davon für lange Zeit kostenlos sein werden. Aus intuitiven Überlegungen ist klar, dass es anscheinend eine optimale Anzahl von Zeilen N gibt. Wie berechnet man diese Anzahl? Beginnen wir mit einem realistischen Modell, das die Intensität des Zugriffs eines Teilnehmers auf das Netzwerk beschreibt. Beachten Sie, dass die Genauigkeit des Modells natürlich anhand standardmäßiger statistischer Kriterien überprüft werden kann. Nehmen wir also an, dass jeder Teilnehmer die Leitung durchschnittlich 2 Minuten pro Stunde nutzt und die Verbindungen der Teilnehmer unabhängig sind (letzteres tritt jedoch ein, wie Feller zu Recht betont, es sei denn, es tritt ein Ereignis ein, das alle Teilnehmer betrifft, zum Beispiel ein Krieg oder …). ein Hurricane). Dann haben wir 2000 Bernoulli-Versuche (Münzwürfe) oder Netzwerkverbindungen mit einer Erfolgswahrscheinlichkeit p=2/60=1/30. Wir müssen ein N finden, sodass die Wahrscheinlichkeit, dass sich mehr als N Benutzer gleichzeitig mit dem Netzwerk verbinden, 0,01 nicht überschreitet. Diese Berechnungen können im STATISTICA-System einfach gelöst werden. Lösung des Problems mit STATISTICA. Schritt 1.Öffnen Sie das Modul Grundlegende Statistiken. Erstellen Sie eine binoml.sta-Datei mit 110 Beobachtungen. Benennen Sie die erste Variable BINOMIAL, die zweite Variable - POISSON. Schritt 2. BINOMIAL, Öffne das Fenster Variable 1(siehe Bild). Geben Sie die Formel wie in der Abbildung gezeigt in das Fenster ein. Drück den Knopf OK. Schritt 3. Doppelklicken Sie auf den Titel POISSON, Öffne das Fenster Variable 2(siehe Bild) Geben Sie die Formel wie in der Abbildung gezeigt in das Fenster ein. Beachten Sie, dass wir den Poisson-Verteilungsparameter mithilfe der Formel berechnen =n×p. Daher = 2000 × 1/30. Drück den Knopf OK.
STATISTICA berechnet die Wahrscheinlichkeiten und schreibt sie in die generierte Datei. Schritt 4. Scrollen Sie nach unten zur Beobachtungsnummer 86. Sie werden sehen, dass die Wahrscheinlichkeit von 86 oder mehr gleichzeitigen Benutzern von 2.000 Netzwerkbenutzern in einer Stunde 0,01347 beträgt, wenn die Binomialverteilung verwendet wird. Die Wahrscheinlichkeit, dass 86 oder mehr Personen von 2.000 Netzwerkbenutzern gleichzeitig in einer Stunde arbeiten, beträgt 0,01293, wobei die Poisson-Näherung für die Binomialverteilung verwendet wird. Da wir eine Wahrscheinlichkeit von nicht mehr als 0,01 benötigen, reichen 87 Zeilen aus, um die erforderliche Kommunikationsqualität bereitzustellen. Ähnliche Ergebnisse können erhalten werden, wenn Sie die Normalnäherung für die Binomialverteilung verwenden (sehen Sie sich das an!). Beachten Sie, dass V. Feller nicht über das STATISTICA-System verfügte und Tabellen für Binomial- und Normalverteilungen verwendete. Mit der gleichen Argumentation kann man das folgende von W. Feller diskutierte Problem lösen. Bei der Aufteilung in 2 Gruppen à 1000 Personen ist zu prüfen, ob mehr oder weniger Leitungen erforderlich sind, um die Nutzer zuverlässig bedienen zu können. Es stellt sich heraus, dass bei der Einteilung der Benutzer in Gruppen weitere 10 Zeilen erforderlich sind, um das gleiche Qualitätsniveau zu erreichen. Sie können auch Änderungen der Netzwerkverbindungsintensität im Laufe des Tages berücksichtigen. Geometrische Verteilung Wenn unabhängige Bernoulli-Tests durchgeführt werden und die Anzahl der Versuche bis zum nächsten „Erfolg“ gezählt wird, dann hat diese Zahl eine geometrische Verteilung. Wenn Sie also eine Münze werfen, folgt die Anzahl der Würfe, die Sie durchführen müssen, bevor das nächste Wappen erscheint, einem geometrischen Gesetz. Die geometrische Verteilung wird durch die Formel bestimmt: F(x) = p(1-p) x-1 p - Erfolgswahrscheinlichkeit, x = 1, 2,3... Der Name der Verteilung bezieht sich auf die geometrische Progression. Die geometrische Verteilung gibt also die Wahrscheinlichkeit an, dass ein bestimmter Schritt erfolgreich war. Die geometrische Verteilung ist ein diskretes Analogon der Exponentialverteilung. Wenn sich die Zeit durch Quanten ändert, wird die Erfolgswahrscheinlichkeit zu jedem Zeitpunkt durch ein geometrisches Gesetz beschrieben. Wenn die Zeit kontinuierlich ist, wird die Wahrscheinlichkeit durch ein Exponential- oder Exponentialgesetz beschrieben. Hypergeometrische Verteilung Dies ist eine diskrete Wahrscheinlichkeitsverteilung einer Zufallsvariablen X, die ganzzahlige Werte m = 0, 1,2,...,n mit Wahrscheinlichkeiten annimmt: wobei N, M und n nicht negative ganze Zahlen sind und M<
N, n < N. Die hypergeometrische Verteilung ist normalerweise mit einer ersatzlosen Auswahl verbunden und bestimmt beispielsweise die Wahrscheinlichkeit, in einer Zufallsstichprobe der Größe n aus einer Population mit N Bällen, darunter M Schwarz und N – M Weiß, genau m schwarze Bälle zu finden (siehe z. B Beispiel: Enzyklopädie „Wahrscheinlichkeit“ und mathematische Statistik“, M.: Große russische Enzyklopädie, S. 144). Der mathematische Erwartungswert der hypergeometrischen Verteilung hängt nicht von N ab und stimmt mit dem mathematischen Erwartungswert µ=np der entsprechenden Binomialverteilung überein. Varianz der hypergeometrischen Verteilung Diese Verteilung kommt bei Qualitätskontrollanwendungen äußerst häufig vor. Polynomverteilung Die Polynom- oder Multinomialverteilung verallgemeinert die Verteilung natürlich. Während eine Binomialverteilung auftritt, wenn eine Münze mit zwei Ergebnissen geworfen wird (Kopf oder Kamm), liegt eine Polynomverteilung vor, wenn ein Würfel geworfen wird und es mehr als zwei mögliche Ergebnisse gibt. Formal ist dies eine gemeinsame Wahrscheinlichkeitsverteilung von Zufallsvariablen X 1,...,X k, die nicht negative ganzzahlige Werte n 1,...,n k annimmt und die Bedingung n 1 + ... + n k = erfüllt n, mit Wahrscheinlichkeiten: Der Name „Multinomialverteilung“ erklärt sich aus der Tatsache, dass bei der Entwicklung des Polynoms (p 1 + ... + p k) n multinomiale Wahrscheinlichkeiten entstehen Beta-Verteilung Die Betaverteilung hat eine Dichte der Form: Die Standard-Beta-Verteilung konzentriert sich auf das Intervall von 0 bis 1. Mithilfe linearer Transformationen kann der Beta-Wert so transformiert werden, dass er Werte in jedem Intervall annimmt. Grundlegende numerische Eigenschaften einer Größe mit Beta-Verteilung: Verteilung der Extremwerte Die Verteilung der Extremwerte (Typ I) hat eine Dichte der Form: Diese Verteilung wird manchmal auch Extremwertverteilung genannt. Die Verteilung extremer Werte wird bei der Modellierung extremer Ereignisse verwendet, beispielsweise von Hochwasserständen, Wirbelgeschwindigkeiten, dem Maximum von Börsenindizes für ein bestimmtes Jahr usw. Diese Verteilung wird beispielsweise in der Zuverlässigkeitstheorie zur Beschreibung der Ausfallzeit elektrischer Schaltkreise sowie in versicherungsmathematischen Berechnungen verwendet. Rayleigh-Verteilungen Die Rayleigh-Verteilung hat eine Dichte der Form: wobei b der Skalierungsparameter ist. Die Rayleigh-Verteilung konzentriert sich auf den Bereich von 0 bis unendlich. Anstelle des Werts 0 können Sie in STATISTICA einen anderen Wert für den Schwellenwertparameter eingeben, der von den Originaldaten abgezogen wird, bevor die Rayleigh-Verteilung angepasst wird. Daher muss der Wert des Schwellenwertparameters kleiner sein als alle beobachteten Werte. Wenn zwei Variablen 1 und 2 unabhängig voneinander und mit der gleichen Varianz normalverteilt sind, dann ist die Variable Die Rayleigh-Verteilung wird beispielsweise in der Schießtheorie verwendet. Weibull-Verteilung Die Weibull-Verteilung ist nach dem schwedischen Forscher Waloddi Weibull benannt, der diese Verteilung zur Beschreibung von Ausfallzeiten unterschiedlicher Art in der Zuverlässigkeitstheorie verwendete. Formal wird die Weibull-Verteilungsdichte wie folgt geschrieben: Manchmal wird die Weibull-Verteilungsdichte auch geschrieben als: B – Skalenparameter; C – Formparameter; E ist die Eulersche Konstante (2,718...). Positionsparameter. Typischerweise ist die Weibull-Verteilung auf der Halbachse von 0 bis unendlich zentriert. Führt man statt der Grenze 0 den in der Praxis oft notwendigen Parameter a ein, so entsteht die sogenannte dreiparametrige Weibull-Verteilung. Die Weibull-Verteilung wird häufig in der Zuverlässigkeitstheorie und im Versicherungswesen verwendet. Wie oben beschrieben, wird die Exponentialverteilung häufig als Modell zur Schätzung der Zeit bis zum Ausfall unter der Annahme verwendet, dass die Ausfallwahrscheinlichkeit eines Objekts konstant ist. Ändert sich die Ausfallwahrscheinlichkeit im Laufe der Zeit, kommt die Weibull-Verteilung zur Anwendung. Bei mit =1 oder, in einer anderen Parametrisierung, mit der Weibull-Verteilung, wie aus den Formeln leicht ersichtlich ist, geht in eine Exponentialverteilung über, und mit - in die Rayleigh-Verteilung. Zur Schätzung von Weibull-Verteilungsparametern wurden spezielle Methoden entwickelt (siehe z. B. das Buch: Lawless (1982) Statistical models and Methods for Lifetime Data, Belmont, CA: Lifetime Learning, das Schätzmethoden sowie bei der Schätzung auftretende Probleme beschreibt). der Positionsparameter für eine Drei-Parameter-Verteilung Weibull). Bei der Durchführung von Zuverlässigkeitsanalysen ist es häufig erforderlich, die Ausfallwahrscheinlichkeit innerhalb eines kurzen Zeitintervalls nach dem Zeitpunkt zu berücksichtigen Das habe ich bis jetzt nicht vorausgesetzt Es ist kein Fehler aufgetreten. Diese Funktion wird Risikofunktion oder Ausfallratenfunktion genannt und ist formal wie folgt definiert: H(t) – Ausfallratenfunktion oder Risikofunktion zum Zeitpunkt t; f(t) – Verteilungsdichte der Ausfallzeiten; F(t) – Verteilungsfunktion der Ausfallzeiten (Integral der Dichte über das Intervall). Im Allgemeinen wird die Ausfallratenfunktion wie folgt geschrieben: Wenn die Risikofunktion gleich einer Konstante ist, die dem normalen Betrieb des Geräts entspricht (siehe Formeln). Wenn die Risikofunktion abnimmt, entspricht dies dem Einlaufen des Geräts. Wenn die Risikofunktion abnimmt, entspricht dies der Alterung des Geräts. Typische Risikofunktionen sind in der Grafik dargestellt. Weibull-Dichtediagramme mit verschiedenen Parametern sind unten dargestellt. Es ist auf drei Wertebereiche des Parameters a zu achten: Im ersten Bereich nimmt die Risikofunktion ab (Anpassungszeitraum), im zweiten Bereich ist die Risikofunktion gleich einer Konstante, im dritten Bereich steigt die Risikofunktion. Am Beispiel des Neuwagenkaufs lässt sich das Gesagte leicht nachvollziehen: Zuerst gibt es eine Eingewöhnungsphase des Autos, dann eine lange Zeit des Normalbetriebs, dann verschleißen die Teile des Autos und es besteht die Gefahr eines Ausfalls nimmt stark zu. Wichtig ist, dass alle Betriebsperioden durch die gleiche Verteilungsfamilie beschrieben werden können. Dies ist die Idee hinter der Weibull-Verteilung. Lassen Sie uns die wichtigsten numerischen Merkmale der Weibull-Verteilung vorstellen. Pareto-Verteilung Bei verschiedenen Problemen der angewandten Statistik sind sogenannte abgeschnittene Verteilungen weit verbreitet. Diese Verteilung wird beispielsweise im Versicherungswesen oder in der Besteuerung verwendet, wenn die Zinsen auf Einkünfte gerichtet sind, die einen bestimmten Wert c 0 überschreiten Grundlegende numerische Eigenschaften der Pareto-Verteilung: Logistikverteilung Die logistische Verteilung hat eine Dichtefunktion: A – Positionsparameter; B – Skalenparameter; E - Euler-Zahl (2,71...). Hotelling T 2 Verteilung Diese kontinuierliche Verteilung, zentriert auf dem Intervall (0, Г), hat die Dichte: Wo sind die Parameter? n und k, n >_k >_1, werden Freiheitsgrade genannt. Bei k = 1 Hotelling, die P-Verteilung reduziert sich auf die Student-Verteilung und für alle k >1 kann als Verallgemeinerung der Student-Verteilung auf den multivariaten Fall betrachtet werden. Die Hotelling-Verteilung basiert auf der Normalverteilung. Angenommen, ein k-dimensionaler Zufallsvektor Y habe eine Normalverteilung mit einem Mittelwertvektor Null und einer Kovarianzmatrix. Betrachten wir die Menge wobei Zufallsvektoren Z i unabhängig voneinander und Y sind und auf die gleiche Weise wie Y verteilt sind. Dann hat die Zufallsvariable T 2 =Y T S -1 Y eine T 2 -Hotelling-Verteilung mit n Freiheitsgraden (Y ist ein Spaltenvektor, T ist der Transpositionsoperator). Wo ist die Zufallsvariable? t n hat eine Student-Verteilung mit n Freiheitsgraden (siehe „Probability and Mathematical Statistics“, Encyclopedia, S. 792). Wenn Y eine Normalverteilung mit einem Mittelwert ungleich Null hat, wird die entsprechende Verteilung aufgerufen nicht zentral Hotelling T 2 -Verteilung mit n Freiheitsgraden und Nichtzentralitätsparameter v. Die Hotelling T 2 -Verteilung wird in der mathematischen Statistik in der gleichen Situation wie die Student-^-Verteilung verwendet, jedoch nur im multivariaten Fall. Wenn die Ergebnisse der Beobachtungen X 1,..., X n unabhängige, normalverteilte Zufallsvektoren mit einem Mittelwertvektor µ und einer nicht singulären Kovarianzmatrix sind, dann Statistik verfügt über einen Hotelling T 2 -Verteiler mit n - 1 Freiheitsgrade. Diese Tatsache bildet die Grundlage des Hotelling-Kriteriums. In STATISTICA ist der Hotelling-Test beispielsweise im Basismodul Statistik und Tabellen verfügbar (siehe Dialogbox unten). Maxwell-Verteilung Die Maxwell-Verteilung entstand in der Physik, als sie die Geschwindigkeitsverteilung von Molekülen eines idealen Gases beschrieb. Diese kontinuierliche Verteilung ist auf (0, ) zentriert und hat die Dichte: Die Verteilungsfunktion hat die Form: wobei Ф(x) die Sist. Die Maxwell-Verteilung hat einen positiven Schiefekoeffizienten und einen einzelnen Modus an einem Punkt (d. h. die Verteilung ist unimodal). Die Maxwell-Verteilung hat Endmomente beliebiger Ordnung; mathematischer Erwartungswert und Varianz sind jeweils gleich und Die Maxwell-Verteilung hängt natürlich mit der Normalverteilung zusammen. Wenn X 1, X 2, X 3 unabhängige Zufallsvariablen sind, die eine Normalverteilung mit den Parametern 0 und õ 2 haben, dann ist die Zufallsvariable Cauchy-Verteilung Diese erstaunliche Verteilung hat manchmal keinen Mittelwert, da ihre Dichte sehr langsam gegen Null geht, wenn der absolute Wert von x zunimmt. Solche Verteilungen werden Heavy-Tailed-Verteilungen genannt. Wenn Sie eine Verteilung erstellen müssen, die keinen Mittelwert hat, dann nennen Sie sie sofort Cauchy-Verteilung. Die Cauchy-Verteilung ist unimodal und symmetrisch in Bezug auf den Modus, der sowohl der Median ist als auch eine Dichtefunktion der Form hat: Wo c > 0 - Skalenparameter und a ist der zentrale Parameter, der gleichzeitig die Werte von Modus und Median bestimmt. Das Integral der Dichte, also die Verteilungsfunktion, ergibt sich aus der Beziehung: Studentenverteilung Der englische Statistiker W. Gosset, bekannt unter dem Pseudonym „Student“, der seine Karriere mit einer statistischen Untersuchung der Qualität englischen Bieres begann, kam 1908 zu folgendem Ergebnis. Lassen x 0 , x 1 ,.., x m – unabhängig, (0, s 2) – normalverteilte Zufallsvariablen: Diese Verteilung, jetzt bekannt als Student-Verteilung (abgekürzt als Die t(m)-Verteilung, wobei m die Anzahl der Freiheitsgrade ist, ist die Grundlage des berühmten t-Tests, mit dem die Mittelwerte zweier Grundgesamtheiten verglichen werden sollen. Dichtefunktion f t (x) hängt nicht von der Varianz õ 2 von Zufallsvariablen ab und ist außerdem unimodal und symmetrisch bezüglich des Punktes x = 0. Grundlegende numerische Merkmale der Student-Verteilung: Die t-Verteilung ist in Fällen wichtig, in denen Schätzungen des Mittelwerts berücksichtigt werden und die Stichprobenvarianz unbekannt ist. In diesem Fall werden die Stichprobenvarianz und die t-Verteilung verwendet. Für große Freiheitsgrade (größer als 30) stimmt die t-Verteilung praktisch mit der Standardnormalverteilung überein. Der Graph der t-Verteilungs-Dichtefunktion verformt sich mit zunehmender Anzahl an Freiheitsgraden wie folgt: Die Spitze nimmt zu, die Ausläufer gehen steiler gegen 0 und der Graph der t-Verteilungs-Dichtefunktion scheint seitlich komprimiert zu sein. F-Verteilung Lassen Sie uns überlegen m 1 + m 2 unabhängige und (0, s 2) normalverteilte Größen Offensichtlich kann dieselbe Zufallsvariable auch als das Verhältnis zweier unabhängiger und entsprechend normalisierter Chi-Quadrat-verteilter Variablen und definiert werden Der berühmte englische Statistiker R. Fisher zeigte 1924, dass die Wahrscheinlichkeitsdichte einer Zufallsvariablen F(m 1, m 2) durch die Funktion gegeben ist: wobei Г(ó) der Wert der Eulerschen Gammafunktion ist. Punkt y, und das Gesetz selbst wird F-Verteilung genannt, wobei die Anzahl der Freiheitsgrade des Zählers und des Nenners gleich m,1l m7 ist Grundlegende numerische Eigenschaften der F-Verteilung: Die F-Verteilung erscheint in der Diskriminanzanalyse, Regressionsanalyse, Varianzanalyse und anderen Arten der multivariaten Datenanalyse.






T hat eine Exponentialverteilung mit Parameter (Lambda). Die Exponentialverteilung wird häufig verwendet, um die Abstände zwischen aufeinanderfolgenden Zufallsereignissen zu beschreiben, beispielsweise die Abstände zwischen Besuchen einer unbeliebten Website, da es sich bei diesen Besuchen um seltene Ereignisse handelt.![]()




![]()





























![]()

![]()
![]()







![]() überschreitet nicht die Varianz der Binomialverteilung npq. Bei Momenten beliebiger Ordnung der hypergeometrischen Verteilung neigen sie zu den entsprechenden Werten der Momente der Binomialverteilung.
überschreitet nicht die Varianz der Binomialverteilung npq. Bei Momenten beliebiger Ordnung der hypergeometrischen Verteilung neigen sie zu den entsprechenden Werten der Momente der Binomialverteilung.



![]() wird eine Rayleigh-Verteilung haben.
wird eine Rayleigh-Verteilung haben.


![]()




















![]() hat eine Maxwell-Verteilung. Somit kann die Maxwell-Verteilung als die Verteilung der Länge eines Zufallsvektors betrachtet werden, dessen Koordinaten in einem kartesischen Koordinatensystem im dreidimensionalen Raum unabhängig und normalverteilt mit Mittelwert 0 und Varianz õ 2 sind.
hat eine Maxwell-Verteilung. Somit kann die Maxwell-Verteilung als die Verteilung der Länge eines Zufallsvektors betrachtet werden, dessen Koordinaten in einem kartesischen Koordinatensystem im dreidimensionalen Raum unabhängig und normalverteilt mit Mittelwert 0 und Varianz õ 2 sind.
![]()




![]() und legen
und legen














